The Emissions Modeling Framework (EMF) is a software system designed to solve many long-standing difficulties of emissions modeling identified at EPA. The overall process of emissions modeling involves gathering measured or estimated emissions data into emissions inventories; applying growth and controls information to create future year and controlled emissions inventories; and converting emissions inventories into hourly, gridded, chemically speciated emissions estimates suitable for input into air quality models such as the Community Multiscale Air Quality (CMAQ) model.
This User’s Guide focuses on the data management and analysis capabilities of the EMF. The EMF also contains a Control Strategy Tool (CoST) for developing future year and controlled emissions inventories and is capable of driving SMOKE to develop CMAQ inputs.
Many types of data are involved in the emissions modeling process including:
Quality assurance (QA) is an important component of emissions modeling. Emissions inventories and other modeling data must be analyzed and reviewed for any discrepancies or outlying data points. Data files need to be organized and tracked so changes can be monitored and updates made when new data is available. Running emissions modeling software such as the Sparse Matrix Operator Kernel Emissions (SMOKE) Modeling System requires many configuration options and input files that need to be maintained so that modeling output can be reproduced in the future. At all stages, coordinating tasks and sharing data between different groups of people can be difficult and specialized knowledge may be required to use various tools.
In your emissions modeling work, you may have found yourself asking questions like:
The EMF helps with these issues by using a client-server system where emissions modeling information is centrally stored and can be accessed by multiple users. The EMF integrates quality control processes into its data management to help with development of high quality emissions results. The EMF also organizes emissions modeling data and tracks emissions modeling efforts to aid in reproducibility of emissions modeling results. Additionally, the EMF strives to allow non-experts to use emissions modeling capabilities such as future year projections, spatial allocation, chemical speciation, and temporal allocation.
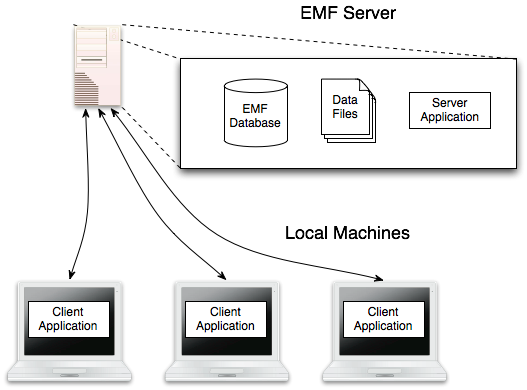
A typical installation of the EMF system is illustrated in Figure 1-1. In this case, a group of users shares a single EMF server with multiple local machines running the client application. The EMF server consists of a database, file storage, and the server application which handles requests from the clients and communicates with the database. The client application runs on each user’s computer and provides a graphical interface for interacting with the emissions modeling data stored on the server (see Chapter 2.). Each user has his or her own username and password for accessing the EMF server. Some users will have administrative privileges which allow them to access additional system data such as managing users or dataset types.
For a simpler setup, all of the EMF components can be run on a single machine: database, server application, and client application. With this “all-in-one” setup, the emissions data would generally not be shared between multiple users.
Figure 1-2 illustrates the basic workflow of data in the EMF system.
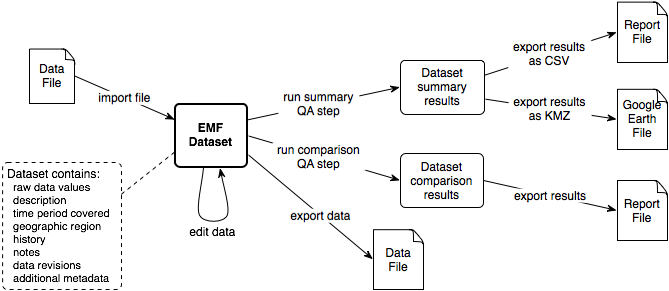
Emissions modeling data files are imported into the EMF system where they are represented as datasets (see Chapter 3.). The EMF supports many different types of data files including emissions inventories, allocation factors, cross-reference files, and reference data. Each dataset matches a dataset type which defines the format of the data to be loaded from the file (Section 3.2). In addition to the raw data values, the EMF stores various metadata about each dataset including the time period covered, geographic region, the history of the data, and data usage in model runs or QA analysis.
Once your data is stored as a dataset, you can review and edit the dataset’s properties (Section 3.5) or the data itself (Section 3.6) using the EMF client. You can also run QA steps on a dataset or set of datasets to extract summary information, compare datasets, or convert the data to a different format (see Chapter 4.).
You can export your dataset to a file and download it to your local computer (Section 3.8). You can also export reports that you create with QA steps for further analysis in a spreadsheet program or to create charts (Section 4.5).
The EMF client is a graphical desktop application written in Java. While it is primarily developed and used in Windows, it will run under Mac OS X and Linux (although due to font differences the window layout may not be optimal). The EMF client can be run on Windows XP, Windows 7, or Windows 8.
The EMF requires Java 6 or greater. The following instructions will help you check if you have Java installed on your Windows machine and what version is installed. If you need more details, please visit How to find Java version in Windows [java.com].
The latest version(s) of Java on your system will be listed as Java 7 with an associated Update number (eg. Java 7 Update 21). Older versions may be listed as Java(TM), Java Runtime Environment, Java SE, J2SE or Java 2.
Windows 8
Windows 7 and Vista
Windows XP
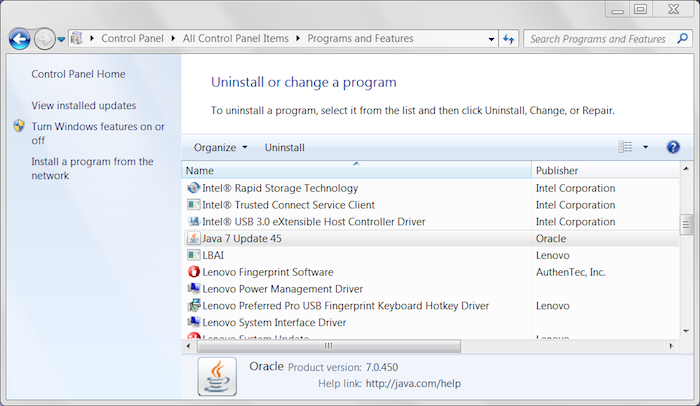
Figure 2-1 shows the Programs and Features Control Panel on Windows 7 with Java installed. The installed version of Java is Version 7 Update 45; this version does not need to be updated to run the EMF client.
If you need to install Java, please follow the instructions for downloading and installing Java for a Windows computer [java.com]. Note that you will need administrator privileges to install Java on Windows. During the installation, make a note of the directory where Java is installed on your computer. You will need this information to configure the EMF client.
If Java is installed on your computer but is not version 6 or greater, you will need to update your Java installation. Start by opening the Java Control Panel from the Windows Control Panel. Figure 2-2 shows the Java Control Panel.
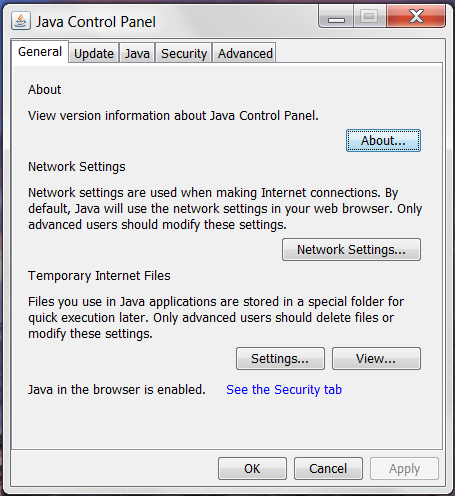
Clicking the About button will display the Java version dialog seen in Figure 2-3. In Figure 2-3, the installed version of Java is Version 7 Update 45. This version of Java does not need to be updated to run the EMF client.

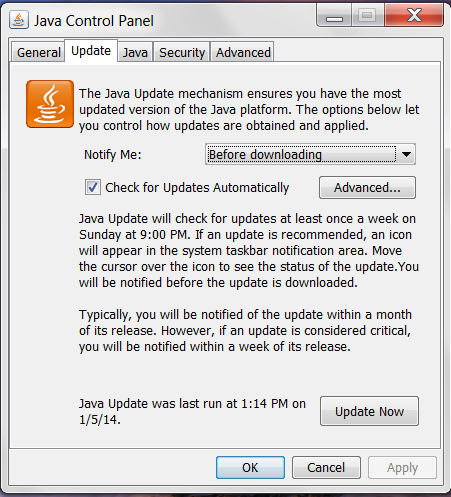
To update Java, click the tab labeled Update in the Java Control Panel (see Figure 2-4). Click the button labeled Update Now in the bottom right corner of the Java Control Panel to update your installation of Java.
The following instructions are specific to the MARAMA EMF installation.
To get started, please contact MARAMA to request the EMF client package. Click on the folder named EMF_State. You should see a page similar to Figure 2-5.
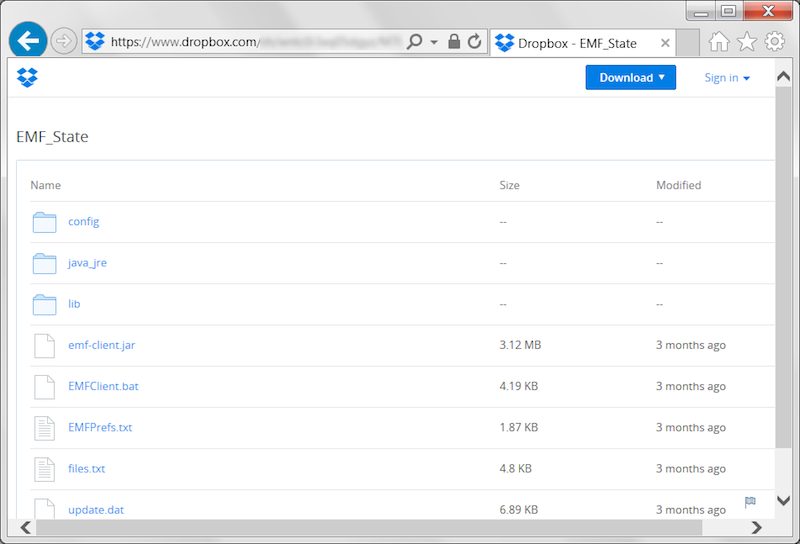
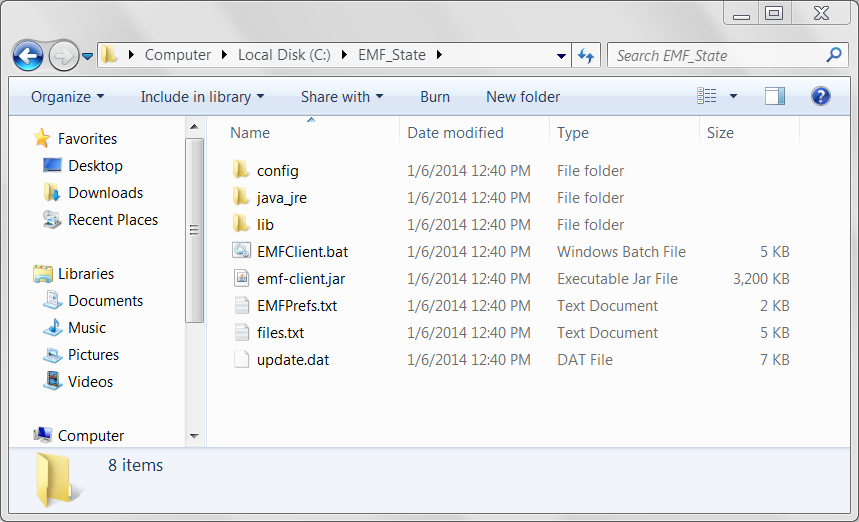
In the top right corner of the window, click the Download button and choose “Download as .zip”. Once the file EMF_State.zip has finished downloading, open the zip file and drag the folder EMF_State to your C: drive. You want to end up with the directory C:\EMF_State as shown in Figure 2-6. You may need administrator privileges to drag the folder to the C: drive.
Next, determine the location where Java is installed on your computer. Depending on the version of your operating system and which version of Java you have, the location might be:
If the location of your Java executable is anything other than C:\Program Files\Java\jre6\bin\java, you will need to edit the EMFClient.bat file in the C:\EMF_State directory. Right click on the EMFClient.bat file and select Edit to open the file in Notepad. You should see a file like Figure 2-7.
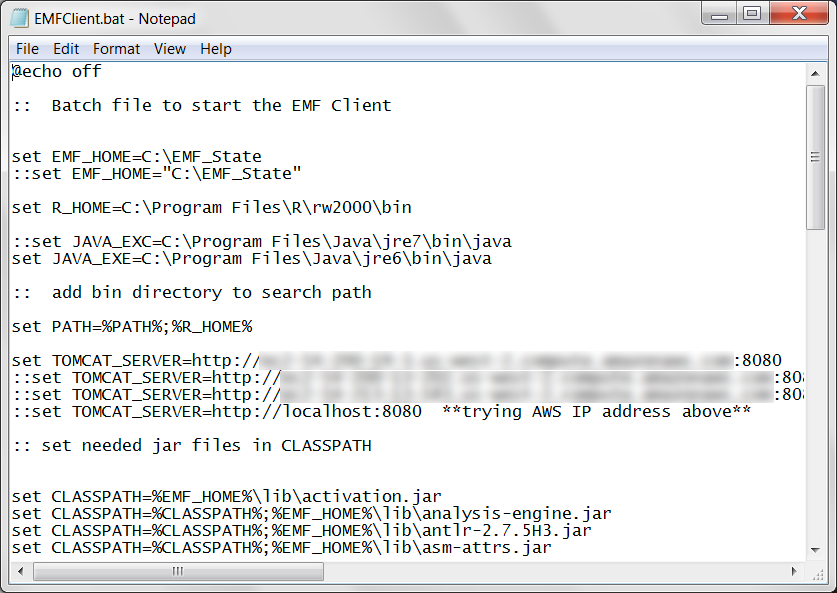
Find the line
set JAVA_EXE=C:\Program Files\Java\jre6\bin\java
and update the location to match your Java installation. Save the file and close Notepad.
To launch the EMF client, double-click the file named EMFClient.bat. You may see a security warning similar to Figure 2-8. Uncheck the box labeled “Always ask before opening this file” to avoid the warning in the future.
When you start the EMF client application, you will initially see a login window like Figure 2-9.
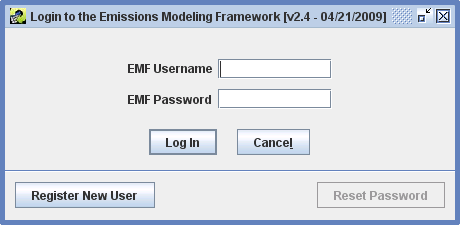
If you are an existing EMF user, enter your EMF username and password in the login window and click the Log In button. If you forget your password, an EMF Administrator can reset it for you. Note: The Reset Password button is used to update your password when it expires; it can’t be used if you’ve lost your password. See Section 2.5 for more information on password expiration.
If you have never used the EMF before, click the Register New User button to bring up the Register New User window as shown in Figure 2-10.
In the Register New User window, enter the following information:
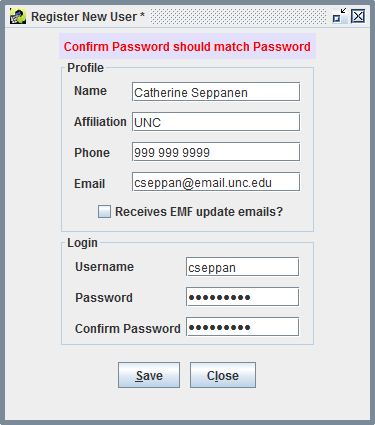
Click OK to create your account. If there are any problems with the information you entered, an error message will be displayed at the top of the window as shown in Figure 2-11.
Once you have corrected any errors, your account will be created and the EMF main window will be displayed (Figure 2-12).
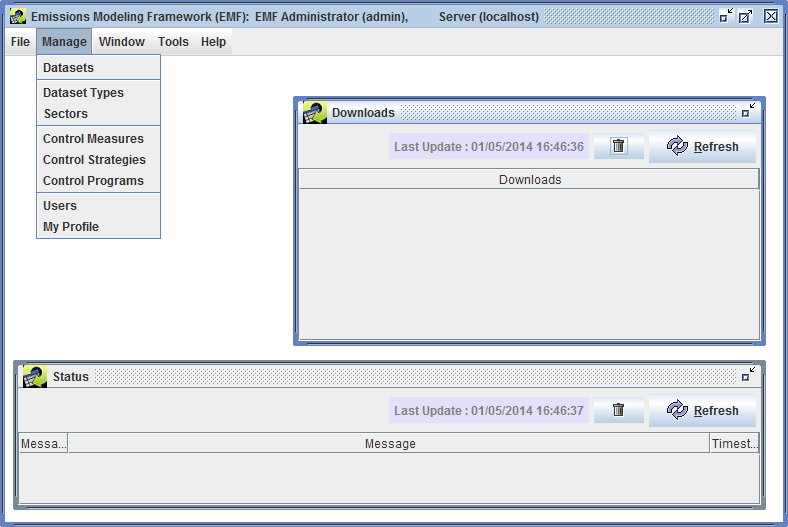
If you need to update any of your profile information or change your password, click the Manage menu and select My Profile to bring up the Edit User window shown in Figure 2-13.
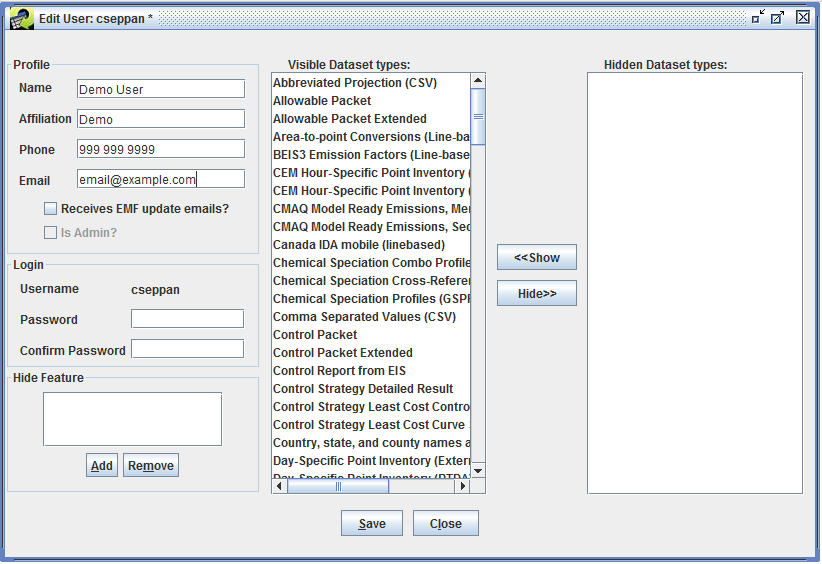
To change your password, enter your new password in the Password field and be sure to enter the same password in the Confirm Password field. Your password must be at least 8 characters long and must contain at least one digit.
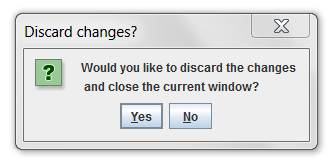
Once you have entered any updated information, click the Save button to save your changes and close the Edit User window. You can close the window without saving changes by clicking the Close button. If you have unsaved changes, you will be asked to confirm that you want to discard your changes (Figure 2-14).
Passwords in the EMF expire every 90 days. If you try to log in and your password has expired, you will see the message “Password has expired. Reset Password.” as shown in Figure 2-15.
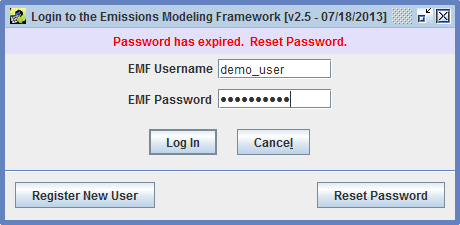
Click the Reset Password button to set a new password as shown in Figure 2-16. After entering your new password and confirming it, click the Save button to save your new password and you will be logged in to the EMF. Make sure to use your new password next time you log in.
As you become familiar with the EMF client application, you’ll encounter various concepts that are reused through the interface. In this section, we’ll briefly introduce these concepts. You’ll see specific examples in the following chapters of this guide.
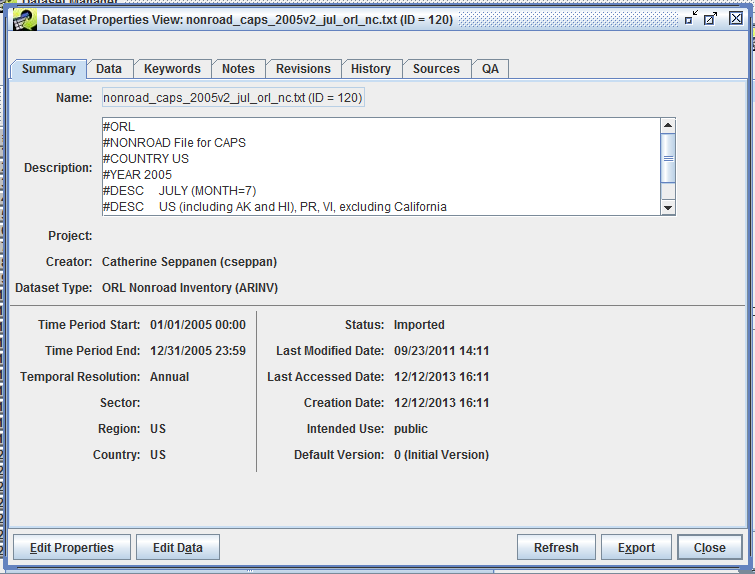
First, we’ll discuss the difference between viewing an item and editing an item. Viewing something in the EMF means that you are just looking at it and can’t change its information. Conversely, editing an item means that you have the ability to change something. Oftentimes, the interface for viewing vs. editing will look similar but when you’re just viewing an item, various fields won’t be editable. For example, Figure 2-17 shows the Dataset Properties View window while Figure 2-18 shows the Dataset Properties Editor window for the same dataset.
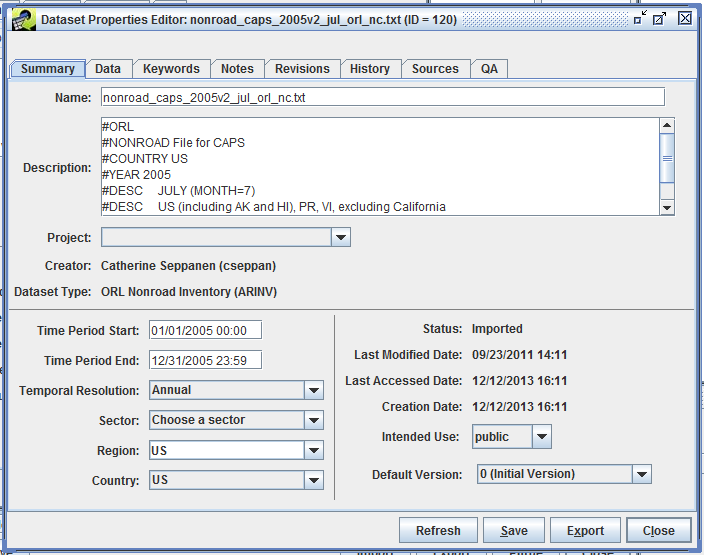
In the edit window, you can make various changes to the dataset like editing the dataset name, selecting the temporal resolution, or changing the geographic region. Clicking the Save button will save your changes. In the viewing window, those same fields are not editable and there is no Save button. Notice in the lower left hand corner of Figure 2-17 the button labeled Edit Properties. Clicking this button will bring up the editing window shown in Figure 2-18.
Similarly, Figure 2-19 shows the QA tab of the Dataset Properties View as compared to Figure 2-20 showing the same QA tab but in the Dataset Properties Editor.
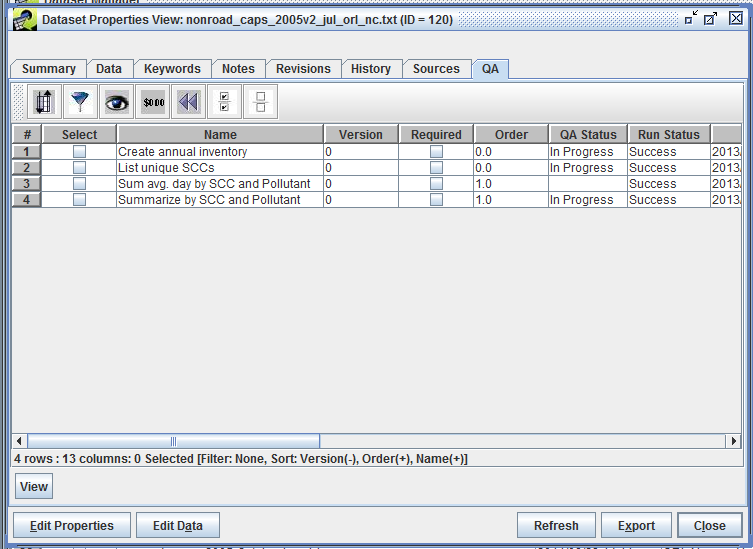
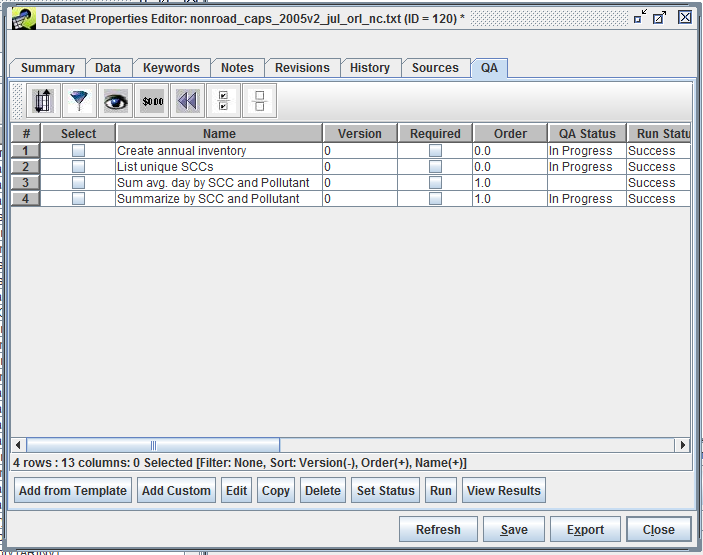
In the View window, the only option is to view each QA step whereas the Editor allows you to interact with the QA steps by adding, editing, copying, deleting, or running the steps. If you are having trouble finding an option you’re looking for, check to see if you’re viewing an item vs. editing it.
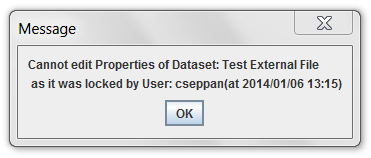
Only one user can edit a given item at a time. Thus, if you are editing a dataset, you have a “lock” on it and no one else will be able to edit it at the same time. Other users will be able to view the dataset as you’re editing it. If you try to edit a locked dataset, the EMF will display a message like Figure 2-21. For some items in the EMF, you may only be able to edit the item if you created it or if your account has administrative privileges.
Generally you will need to click the Save button to save changes that you make. If you have unsaved changes and click the Close button, you will be asked if you want to discard your changes as shown in Figure 2-14. This helps to prevent losing your work if you accidentally close a window.
The EMF client application loads data from the EMF server. As you and other users work, your information is saved to the server. In order to see the latest information from other users, the client application needs to refresh its information by contacting the server. The latest data will be loaded from the server when you open a new window. If you are working in an already open window, you may need to click on the Refresh button to load the newest data. Figure 2-22 highlights the Refresh button in the Dataset Manager window. Clicking Refresh will contact the server and load the latest list of datasets.
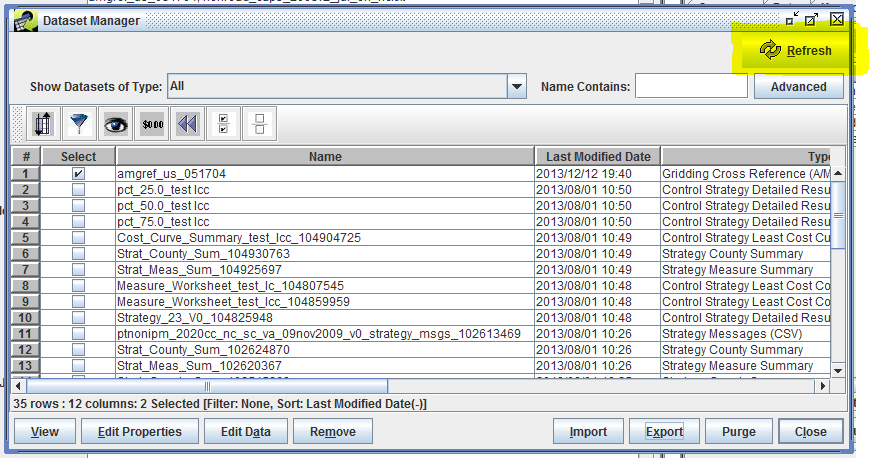
Various windows in the EMF client application have Refresh buttons, usually in either the top right corner as in Figure 2-22 or in the row of buttons on the bottom right like in Figure 2-20.
You will also need to use the Refresh button if you have made changes and return to a previously opened window. For example, suppose you select a dataset in the Dataset Manager and edit the dataset’s name as described in Section 3.5. When you save your changes, the previously opened Dataset Manager window won’t automatically display the updated name. If you close and re-open the Dataset Manager, the dataset’s name will be refreshed; otherwise, you can click the Refresh button to update the display.
Many actions in the EMF are run on the server. For example, when you run a QA step, the client application on your computer sends a message to the server to start running the step. Depending on the type of QA step, this processing can take a while and so the client will allow you to do other work while it periodically checks with the server to find out the status of your request. These status checks are displayed in the Status Window shown in Figure 2-23.
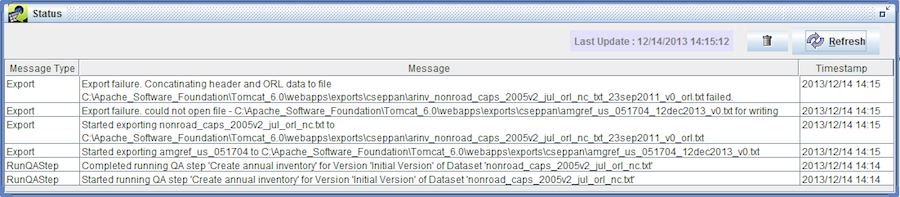
The status window will show you messages about tasks when they are started and completed. Also, error messages will be displayed if a task could not be completed. You can click the Refresh button in the Status Window to refresh the status. The Trash icon clears the Status Window.
Most lists of data within the EMF are displayed using the Sort-Filter-Select Table, a generic table that allows sorting, filtering, and selection (as the name suggests). Figure 2-24 shows the sort-filter-select table used in the Dataset Manager. (To follow along with the figures, select the main Manage menu and then select Datasets. In the window that appears, find the Show Datasets of Type pull-down menu near the top of the window and select All.)
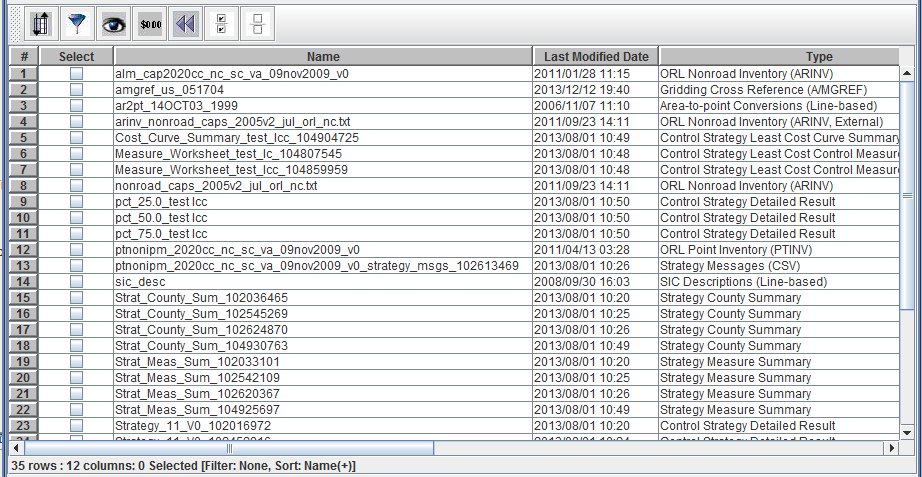
Row numbers are shown in the first column, while the first row displays column headers. The column labeled Select allows you to select individual rows by checking the box in the column. Selections are used for different activities depending on where the table is displayed. For example, in the Dataset Manager window you can select various datasets and then click the View button to view the dataset properties of each selected dataset. In other contexts, you may have options to change the status of all the selected items or copy the selected items. There are toolbar buttons to allow you to quickly select all items in a table (Section 2.6.12) and to clear all selections (Section 2.6.13).
The horizontal scroll bar at the bottom indicates that there are more columns in the table than fit in the window. Scroll to the right in order to see all the columns as in Figure 2-25.
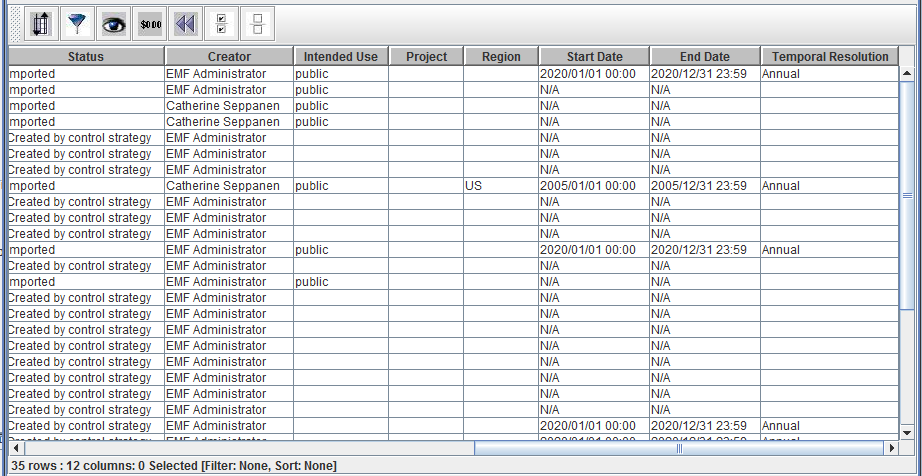
Notice the info line displayed at the bottom of the table. In Figure 2-25 the line reads 35 rows : 12 columns: 0 Selected [Filter: None, Sort: None]. This line gives information about the total number of rows and columns in the table, the number of selected items, and any filtering or sorting applied.
Columns can be resized by clicking on the border between two column headers and dragging it right or left. Your mouse cursor will change to a horizontal double-headed arrow when resizing columns.
You can rearrange the order of the columns in the table by clicking a column header and dragging the column to a new position. Figure 2-26 shows the sort-filter-select table with columns rearranged and resized.
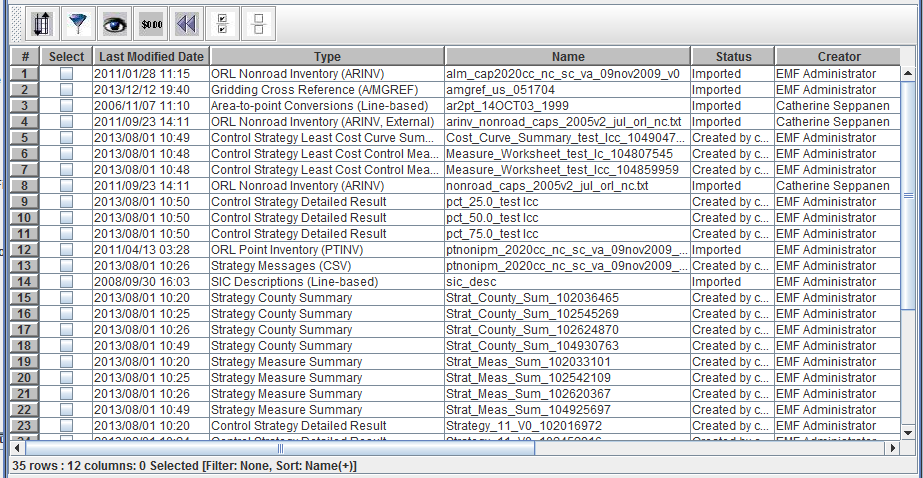
To sort the table using data from a given column, click on the column header such as Last Modified Date. Figure 2-27 shows the table sorted by Last Modified Date in descending order (latest dates first). The table info line now includes Sort: Last Modified Date(-).
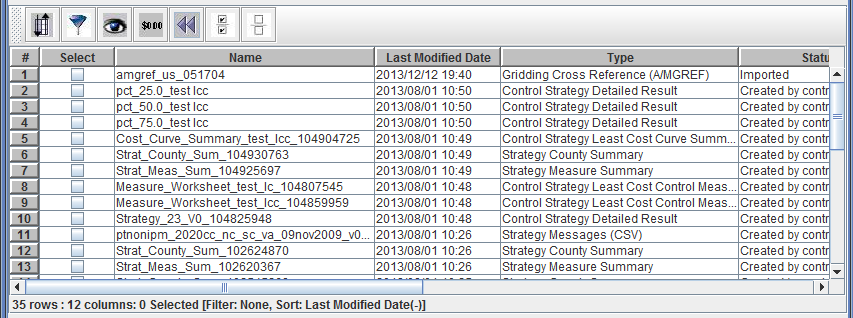
If you click the Last Modified Date header again, the table will re-sort by Last Modified Date in ascending order (earliest dates first). The table info line also changes to Sort: Last Modified Date(+) as seen in Figure 2-28.
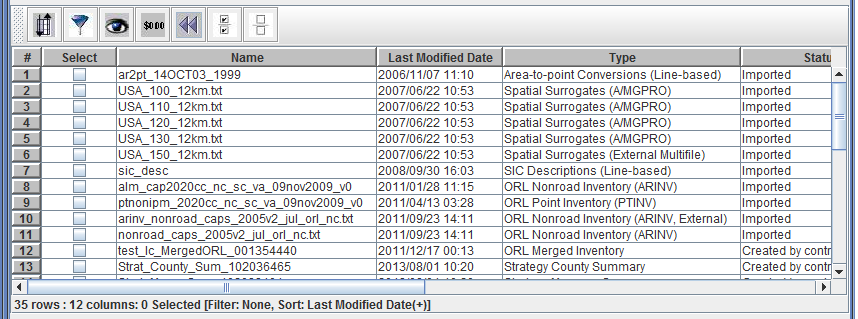
The toolbar at the top of the table (as shown in Figure 2-29) has buttons for the following actions (from left to right):

If you hover your mouse over any of the buttons, a tooltip will pop up to remind you of each button’s function.

The Sort toolbar button brings up the Sort Columns dialog as shown in Figure 2-30. This dialog allows you to sort the table by multiple columns and also allows case sensitive sorting. (Quick sorting by clicking a column header uses case insensitive sorting.)
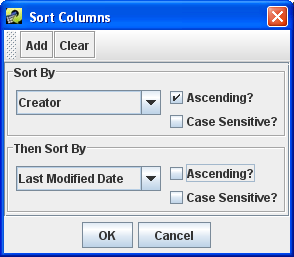
In the Sort Columns Dialog, select the first column you would use to sort the data from the Sort By pull-down menu. You can also specify if the sort order should be ascending or descending and if the sort comparison should be case sensitive.
To add additional columns to sort by, click the Add button and then select the column in the new Then Sort By pull-down menu. When you have finished setting up your sort selections, click the OK button to close the dialog and re-sort the table. The info line beneath the table will show all the columns used for sorting like Sort: Creator(+), Last Modified Date(-).
To remove your custom sorting, click the Clear button in the Sort Columns dialog and then click the OK button. You can also use the Reset toolbar button to reset all custom settings as described in Section 2.6.11.

The Filter Rows toolbar button brings up the Filter Rows dialog as shown in Figure 2-31. This dialog allows you to create filters to “whittle down” the rows of data shown in the table. You can filter the table’s rows based on any column with several different value matching options.
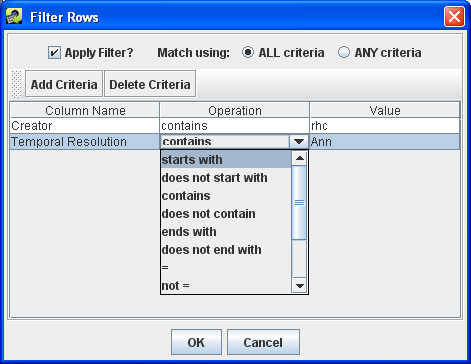
To add a filter criterion, click the Add Criteria button and a new row will appear in the dialog window. Clicking the cell directly under the Column Name header displays a pull-down menu to pick which column you would like use to filter the rows. The Operation column allows you to select how the filter should be applied; for example, you can filter for data that starts with the given value or does not contain the value. Finally, click the cell under the Value header and type in the value to use. Note that the filter values are case-sensitive. A filter value of “nonroad” would not match the dataset type “ORL Nonroad Inventory”.
If you want to specify additional criteria, click Add Criteria again and follow the same process. To remove a filter criterion, click on the row you want to remove and then click the Delete Criteria button.
If the radio button labeled Match using: is set to ALL criteria, then only rows that match all the specified criteria will be shown in the filtered table. If Match using: is set to ANY criteria, then rows will be shown if they meet any of the criteria listed.
Once you are done specifying your filter options, click the OK button to close the dialog and return to the filtered table. The info line beneath the table will include your filter criteria like Filter: Creator contains rhc, Temporal Resolution starts with Ann.
To remove your custom filtering, you can delete the filter criteria from the Filter Rows dialog or uncheck the Apply Filter? checkbox to turn off the filtering without deleting your filter rules. You can also use the Reset toolbar button to reset all custom settings as described in Section 2.6.11. Note that clicking the Reset button will delete your filter rules.

The Show/Hide Columns toolbar button brings up the Show/Hide Columns dialog as shown in Figure 2-32. This dialog allows you to customize which columns are displayed in the table.
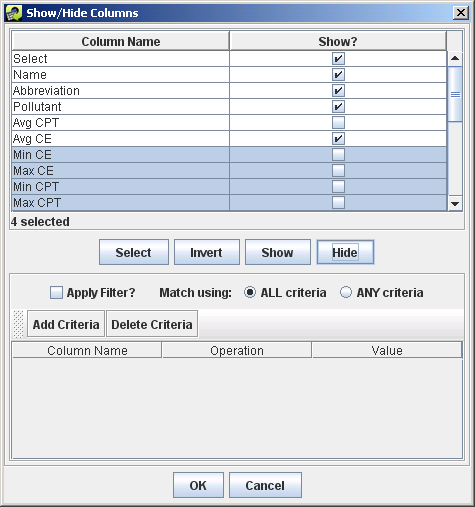
To hide a column, uncheck the box next to the column name under the Show? column. Click the OK button to return to the table. The columns you unchecked will no longer be seen in the table. The info line beneath the table will also be updated with the current number of displayed columns.
To make a hidden column appear again, open the Show/Hide Columns dialog and check the Show? box next to the hidden column’s name. Click OK to close the Show/Hide Columns dialog.
To select multiple columns to show or hide, click on the first column name of interest. Then hold down the Shift key and click a second column name to select it and the intervening columns. Once rows are selected, clicking the Show or Hide buttons in the middle of the dialog will check or uncheck all the Show? boxes for the selected rows. To select multiple rows that aren’t next to each other, you can hold down the Control key while clicking each row. The Invert button will invert the selected rows. After checking/unchecking the Show? checkboxes, click OK to return to the table with the columns shown/hidden as desired.
The Show/Hide Columns dialog also supports filtering to find columns to show or hide. This is an infrequently used option most useful for locating columns to show or hide when there are many columns in the table. Figure 2-33 shows an example where a filter has been set up to match column names that contain the value “Date”. Clicking the Select button above the filtering options selects matching rows which can then be hidden by clicking the Hide button.
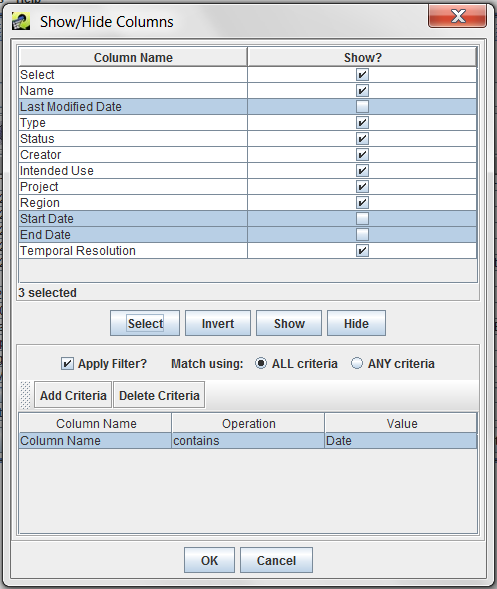

The Format Columns toolbar button displays the Format Columns dialog show in Figure 2-34. This dialog allows you to customize the formatting of columns. In practice, this dialog is not used very often but it can be helpful to format numeric data by changing the number of decimal places or the number of significant digits shown.
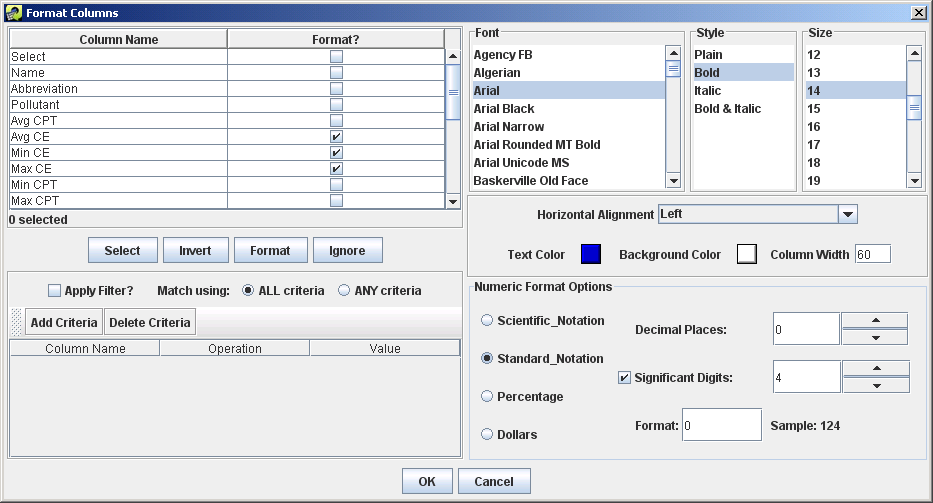
To change the format of a column, first check the checkbox next to the column name in the Format? column. If you only select columns that contain numeric data, the Numeric Format Options section of the dialog will appear; otherwise, it will not be visible. The Format Columns dialog supports filtering by column name similar to the Show/Hide Columns dialog (Section 2.6.9).
From the Format Columns dialog, you can change the font, the style of the font (e.g. bold, italic), the horizontal alignment for the column (e.g. left, center, right), the text color, and the column width. For numeric columns, you can specify the number of significant digits and decimal places.

The Reset toolbar button will remove all customizations from the table: sorting, filtering, hidden columns, and formatting. It will also reset the column order and set column widths back to the default.

The Select All toolbar button selects all the rows in the table. After clicking the Select All button, you will see that the checkboxes in the Select column are now all checked. You can select or deselect an individual item by clicking its checkbox in the Select column.
The Clear All Selections toolbar button unselects all the rows in the table.
Emissions inventories, reference data, and other types of data files are imported into the EMF and stored as datasets. A dataset encompasses both the data itself as well as various dataset properties such as the time period covered by the dataset and geographic extent of the dataset. Changes to a dataset are tracked as dataset revisions. Multiple versions of the data for a dataset can be stored in the EMF.
Each dataset has a dataset type. The dataset type describes the format of the dataset’s data. For example, the dataset type for an ORL Point Inventory (PTINV) defines the various data fields of the inventory file such as FIPS code, SCC code, pollutant name, and annual emissions value. A different dataset type like Spatial Surrogates (A/MGPRO) defines the fields in the corresponding file: surrogate code, FIPS code, grid cell, and surrogate fraction.
The EMF also supports flexible dataset types without fixed format - Comma Separated Value and Line-based. These types allow for new kinds of data to be loaded into the EMF without requiring updates to the EMF software.
When importing data into the EMF, you can choose between internal dataset types where the data itself is stored in the EMF database and external dataset types where the data remains in a file on disk and the EMF only tracks the metadata. For internal datasets, the EMF provides data editing, revision and version tracking, and data analysis using SQL queries. External datasets can be used to track files that don’t need these features or data that can’t be loaded into the EMF like binary NetCDF files.
You can view the dataset types defined in the EMF by selecting Dataset Types from the main Manage menu. EMF administrators can add, edit, and remove dataset types; non-administrative users can view the dataset types. Figure 3-1 shows the Dataset Type Manager.
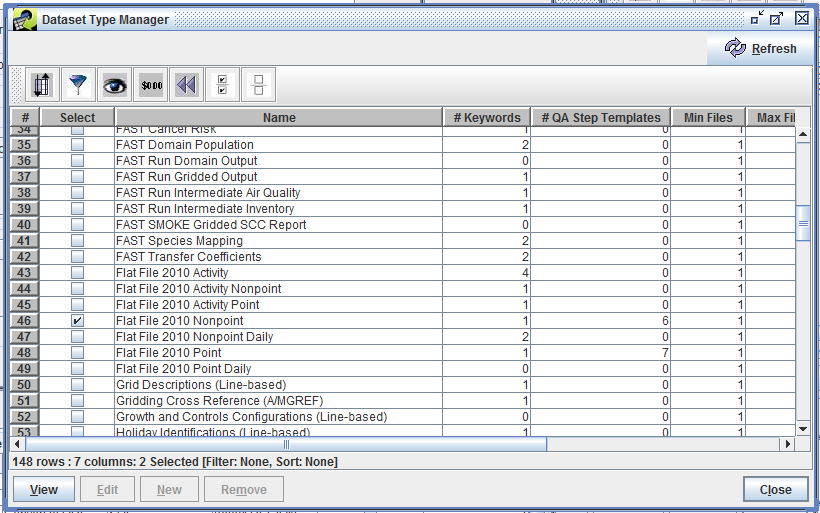
To view the details of a particular dataset type, check the box next to the type you want to view (for example, “Flat File 2010 Nonpoint”) and then click the View button in the bottom left-hand corner.
Figure 3-2 shows the View Dataset Type window for the Flat File 2010 Nonpoint dataset type. Each dataset type has a name and a description along with metadata about who created the dataset type and when, and also the last modified date for the dataset type.
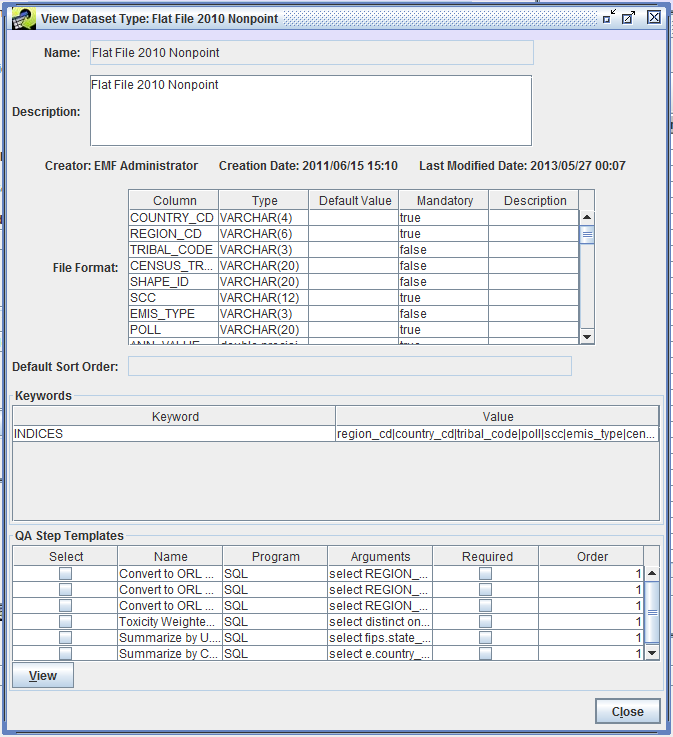
The dataset type defines the format of the data file as seen in the File Format section of Figure 3-2. For the Flat File 2010 Nonpoint dataset type, the columns from the raw data file are mapped into columns in the database when the data is imported. Each data column must match the type (string, integer, floating point) and can be mandatory or optional.
Keyword-value pairs can be used to give the EMF more information about a dataset type. Table 3-1 lists some of the keywords available. Section 3.5.3 provides more information about using and adding keywords.
| Keyword | Description | Example |
|---|---|---|
| EXPORT_COLUMN_LABEL | Indicates if columns labels should be included when exporting the data to a file | FALSE |
| EXPORT_HEADER_COMMENTS | Indicates if header comments should be included when exporting the data to a file | FALSE |
| EXPORT_INLINE_COMMENTS | Indicates if inline comments should be included when exporting the data to a file | FALSE |
| EXPORT_PREFIX | Filename prefix to include when exporting the data to a file | ptinv_ |
| EXPORT_SUFFIX | Filename suffix to use when exporting the data to a file | .csv |
| INDICES | Tells the system to create indices in the database on the given columns | region_cd|country_cd|scc |
| REQUIRED_HEADER | Indicates a line that must occur in the header of a data file | #FORMAT=FF10_ACTIVITY |
Each dataset type can have QA step templates assigned. These are QA steps that apply to any dataset of the given type. More information about using QA step templates in given in Chapter 4..
Dataset types can be added, edited, or deleted by EMF administrators. In this section, we list dataset types that are commonly used. Your EMF installation may not include all of these types or may have additional types defined.
| Dataset Type Name | Description | Link to File Format |
|---|---|---|
| Day-Specific Point Inventory (PTDAY) | Point day-specific emissions inventory in EMS–95 format | SMOKE documentation |
| Flat File 2010 Activity | Onroad mobile activity data (VMT, VPOP, speed) in Flat File 2010 (FF10) format | SMOKE documentation |
| Flat File 2010 Activity Nonpoint | Nonpoint activity data in FF10 format | Same format as Flat File 2010 Activity |
| Flat File 2010 Activity Point | Point activity data in FF10 format | Not available |
| Flat File 2010 Nonpoint | Nonpoint or nonroad emissions inventory in FF10 format | SMOKE documentation |
| Flat File 2010 Nonpoint Daily | Nonpoint or nonroad day-specific emissions inventory in FF10 format | SMOKE documentation |
| Flat File 2010 Point | Point emissions inventory in FF10 format | SMOKE documentation |
| Flat File 2010 Point Daily | Point day-specific emissions inventory in FF10 format | SMOKE documentation |
| IDA Activity | Onroad mobile activity data in IDA format | SMOKE documentation |
| IDA Mobile | Onroad mobile emissions inventory in IDA format | SMOKE documentation |
| IDA Nonpoint/Nonroad | Nonpoint or nonroad emissions inventory in IDA format | SMOKE documentation |
| IDA Point | Point emissions inventory in IDA format | SMOKE documentation |
| Individual Hour-Specific Point Inventory | Point hour-specific emissions inventory in EMS–95 format | SMOKE documentation |
| ORL Day-Specific Fires Data Inventory (PTDAY) | Day-specific fires inventory | SMOKE documentation |
| ORL Fire Inventory (PTINV) | Wildfire and prescribed fire inventory | SMOKE documentation |
| ORL Nonpoint Inventory (ARINV) | Nonpoint emissions inventory in ORL format | SMOKE documentation |
| ORL Nonroad Inventory (ARINV) | Nonroad emissions inventory in ORL format | SMOKE documentation |
| ORL Onroad Inventory (MBINV) | Onroad mobile emissions inventory in ORL format | SMOKE documentation |
| ORL Point Inventory (PTINV) | Point emissions inventory in ORL format | SMOKE documentation |
| Dataset Type Name | Description | Link to File Format |
|---|---|---|
| Country, state, and county names and data (COSTCY) | List of region names and codes with default time zones and daylight-saving time flags | SMOKE documentation |
| Grid Descriptions (Line-based) | List of projections and grids | I/O API documentation |
| Holiday Identifications (Line-based) | Holidays date list | SMOKE documentation |
| Inventory Table Data (INVTABLE) | Pollutant reference data | SMOKE documentation |
| MACT description (MACTDESC) | List of MACT codes and descriptions | SMOKE documentation |
| NAICS description file (NAICSDESC) | List of NAICS codes and descriptions | SMOKE documentation |
| ORIS Description (ORISDESC) | List of ORIS codes and descriptions | SMOKE documentation |
| Point-Source Stack Replacements (PSTK) | Replacement stack parameters | SMOKE documentation |
| SCC Descriptions (Line-based) | List of SCC codes and descriptions | SMOKE documentation |
| SIC Descriptions (Line-based) | List of SIC codes and descriptions | SMOKE documentation |
| Surrogate Descriptions (SRGDESC) | List of surrogate codes and descriptions | SMOKE documentation |
| Dataset Type Name | Description | Link to File Format |
|---|---|---|
| Area-to-point Conversions (Line-based) | Point locations to assign to stationary area and nonroad mobile sources | SMOKE documentation |
| Chemical Speciation Combo Profiles (GSPRO_COMBO) | Multiple speciation profile combination data | SMOKE documentation |
| Chemical Speciation Cross-Reference (GSREF) | Cross-reference data to match inventory sources to speciation profiles | SMOKE documentation |
| Chemical Speciation Profiles (GSPRO) | Factors to allocate inventory pollutant emissions to model species | SMOKE documentation |
| Gridding Cross Reference (A/MGREF) | Cross-reference data to match inventory sources to spatial surrogates | SMOKE documentation |
| Pollutant to Pollutant Conversion (GSCNV) | Conversion factors when inventory pollutant doesn’t match speciation profile pollutant | SMOKE documentation |
| Spatial Surrogates (A/MGPRO) | Factors to allocate emissions to grid cells | SMOKE documentation |
| Spatial Surrogates (External Multifile) | External dataset type to point to multiple surrogates files on disk | Individual files have same format as Spatial Surrogates (A/MGPRO) |
| Temporal Cross Reference (A/M/PTREF) | Cross-reference data to match inventory sources to temporal profiles | SMOKE documentation |
| Temporal Profile (A/M/PTPRO) | Factors to allocate inventory emissions to hourly estimates | SMOKE documentation |
| Dataset Type Name | Description | Link to File Format |
|---|---|---|
| Allowable Packet | Allowable emissions cap or replacement values | SMOKE documentation |
| Allowable Packet Extended | Allowable emissions cap or replacement values; supports monthly values | Download CSV |
| Control Packet | Control efficiency, rule effectiveness, and rule penetration rate values | SMOKE documentation |
| Control Packet Extended | Control percent reduction values; supports monthly values | Download CSV |
| Control Strategy Detailed Result | Output from CoST | Not available |
| Control Strategy Least Cost Control Measure Worksheet | Output from CoST | Not available |
| Control Strategy Least Cost Curve Summary | Output from CoST | Not available |
| Projection Packet | Factors to grow emissions values into the past or future | SMOKE documentation |
| Projection Packet Extended | Projection factors; supports monthly values | Download CSV |
| Strategy County Summary | Output from CoST | Not available |
| Strategy Impact Summary | Output from CoST | Not available |
| Strategy Measure Summary | Output from CoST | Not available |
| Strategy Messages (CSV) | Output from CoST | Not available |
The main interface for finding and interacting with datasets is the Dataset Manager. To open the Dataset Manager, select the Manage menu at the top of the EMF main window, and then select the Datasets menu item. It may take a little while for the window to appear. As shown in Figure 3-3, the Dataset Manager initially does not show any datasets. This is to avoid loading a potentially large list of datasets from the server.
From the Dataset Manager you can:
To quickly find datasets of interest, you can use the Show Datasets of Type pull-down menu at the top of the Dataset Manager window. Select “ORL Point Inventory (PTINV)” and the datasets matching that Dataset Type are loaded into the Dataset Manager as shown in Figure 3-4.
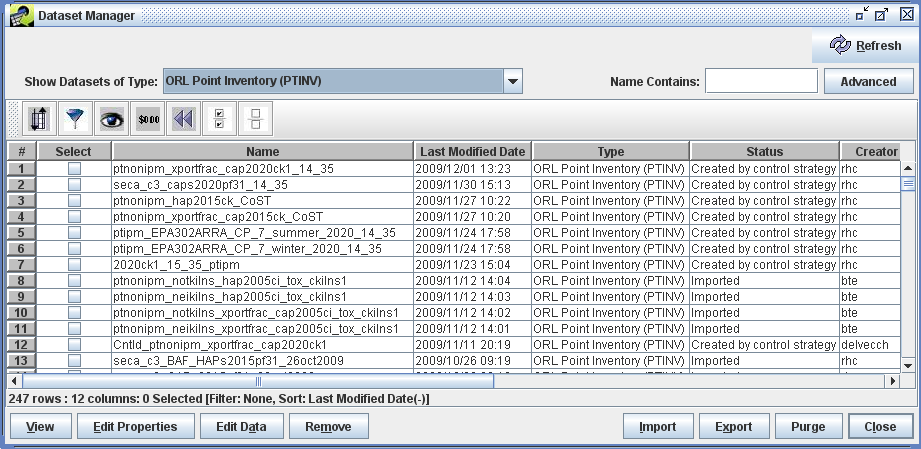
The matching datasets are shown in a table that lists some of their properties, including the dataset’s name, last modified date, dataset type, status indicating how the dataset was created, and the username of the dataset’s creator. Table 3-6 describes each column in the Dataset Manager window. In the Dataset Manager window, use the horizontal scroll bar to scroll the table to the right to see all the columns.
| Column | Description |
|---|---|
| Name | A unique name or label for the dataset. You choose this name when importing data and it can be edited by users with appropriate privileges. |
| Last Modified Date | The most recent date and time when the data (not the metadata) of the dataset was modified. When the dataset is initially imported, the Last Modified Date is set to the file’s timestamp. |
| Type | The Dataset Type of this dataset. The Dataset Type incorporates information about the structure of the data and information regarding how the data can be sorted and summarized. |
| Status | Shows whether the dataset was imported from disk or created in some other way such as an output from a control strategy. |
| Creator | The username of the person who originally created the dataset. |
| Intended Use | Specifies whether the dataset is intended to be public (accessible to any user), private (accessible only to the creator), or to be used by a specific group of users. |
| Project | The name of a study or set of work for which this dataset was created. The project field can help you organize related files. |
| Region | The name of a geographic region to which the dataset applies. |
| Start Date | The start date and time for the data contained in the dataset. |
| End Date | The end date and time for the data contained in the dataset. |
| Temporal Resolution | The temporal resolution of the data contained in the dataset (e.g. annual, daily, or hourly). |
Using the Dataset Manager, you can select datasets of interest by checking the checkboxes in the Select column and then perform various actions related to those datasets. Table 3-7 lists the buttons along the bottom of the Dataset Manager window and describes the actions for each button.
| Command | Description |
|---|---|
| View | Displays a read-only Dataset Properties View for each of the selected datasets. You can view a dataset even when someone else is editing that dataset’s properties or data. |
| Edit Properties | Opens a writeable Dataset Properties Editor for each of the selected datasets. Only one user can edit a dataset at any given time. |
| Edit Data | Opens a Dataset Versions Editor for each of the selected datasets. |
| Remove | Marks each of the selected datasets for deletion. Datasets are not actually deleted until you click purge. |
| Import | Opens the Import Datasets window where you can import data files into the EMF as new datasets. |
| Export | Opens the Export window to write the data for one version of the selected dataset to a file. |
| Purge | Permanently removes any datasets that are marked for deletion from the EMF. |
| Close | Closes the Dataset Manager window. |
There are several ways to find datasets using the Dataset Manager. First, you can show all datasets with a particular dataset type by choosing the dataset type from the Show Datasets of Type menu. If there are more than a couple hundred datasets matching the type you select, the system will warn you and suggest you enter something in the Name Contains field to limit the list.
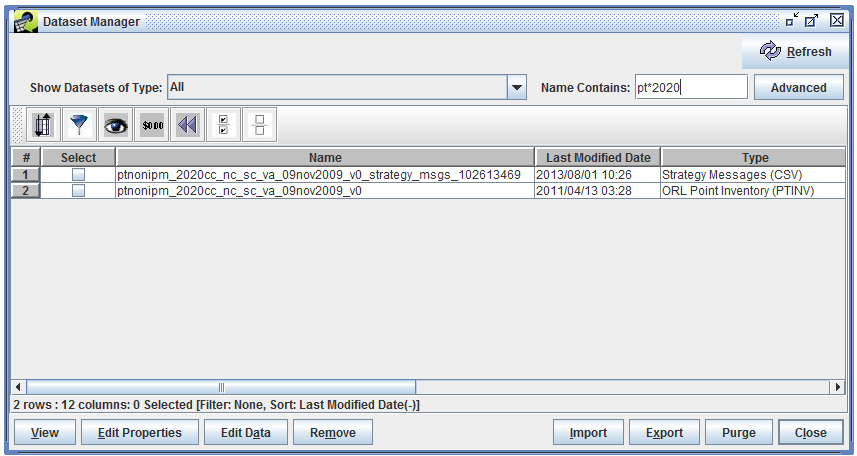
The Name Contains field allows you to enter a search term to match dataset names. For example, if you type 2020 in the textbox and then hit Enter, the Dataset Manager will show all the datasets with “2020” in their names. You can also use wildcards in your keyword. Using the keyword pt*2020 will show all datasets whose name contains “pt” followed at some point by “2020” as shown in Figure 3-5. The Name Contains search is not case sensitive.
If you want to search for datasets using attributes other than the dataset’s name or using multiple criteria, click the Advanced button. The Advanced Dataset Search dialog as shown in Figure 3-6 will be displayed.
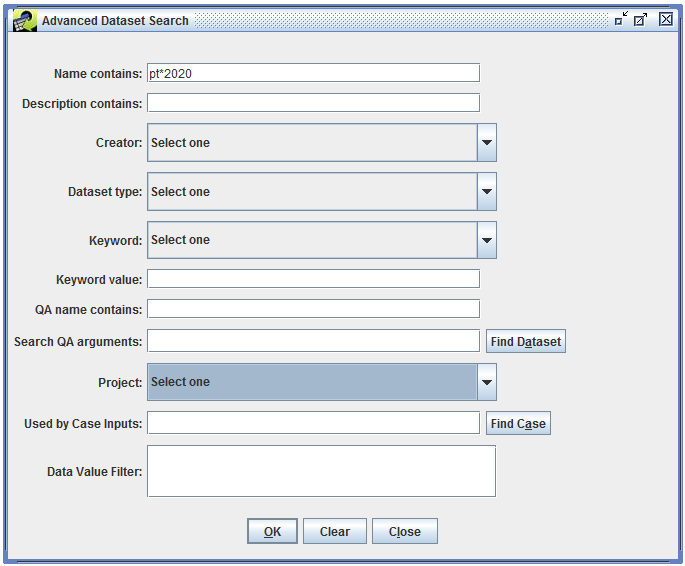
You can use the Advanced Dataset Search to search for datasets based on the contents of the dataset’s description, the dataset’s creator, project, and more. Table 3-8 lists the options for the advanced search.
| Search option | Description |
|---|---|
| Name contains | Performs a case-insensitive search of the dataset name; supports wildcards |
| Description contains | Performs a case-insensitive search of the dataset description; supports wildcards |
| Creator | Matches datasets created by the specified user |
| Dataset type | Matches datasets of the specified type |
| Keyword | Matches datasets that have the specified keyword |
| Keyword value | Matches datasets where the specified keyword has the specified value; must exactly match the dataset’s keyword value (case-insensitive) |
| QA name contains | Performs a case-insensitive search of the names of the QA steps associated with datasets |
| Search QA arguments | Searches the arguments to QA steps associated with datasets |
| Project | Matches datasets assigned to the specified project |
| Used by Case Inputs | Finds datasets by case (not described in this User’s Guide) |
| Data Value Filter | Matches datasets using SQL like “FIPS='37001' and SCC like '102005%'”; must be used with the dataset type criterion |
After setting your search criteria, click OK to perform the search and update the Dataset Manager window. The Advanced Dataset Search dialog will remain visible until you click Close. This allows you to refine your search or perform additional searches if needed. If you specify multiple search criteria, a dataset must satisfy all of the specified criteria to be shown in the Dataset Manager.
Another option for finding datasets is to use the filtering options of the Dataset Manager. (See Section 2.6.8 for a complete description of the Filter Rows dialog.) Filtering helps narrow down the list of datasets already shown in the Dataset Manager. Click the Filter Rows button in the toolbar to bring up the Filter Rows dialog. In the dialog, you can create a filter to show only datasets whose dataset type contains the word “Inventory” (see Figure 3-7).
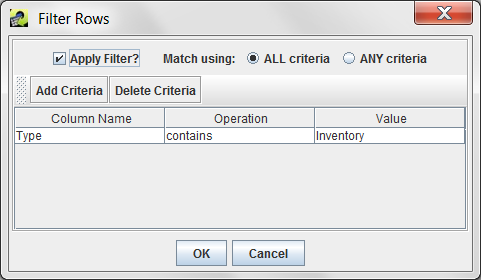
Once you’ve entered the filter criteria, click OK to return to the Dataset Manager. The list of datasets has now been reduced to only those matching the filter as shown in Figure 3-8.
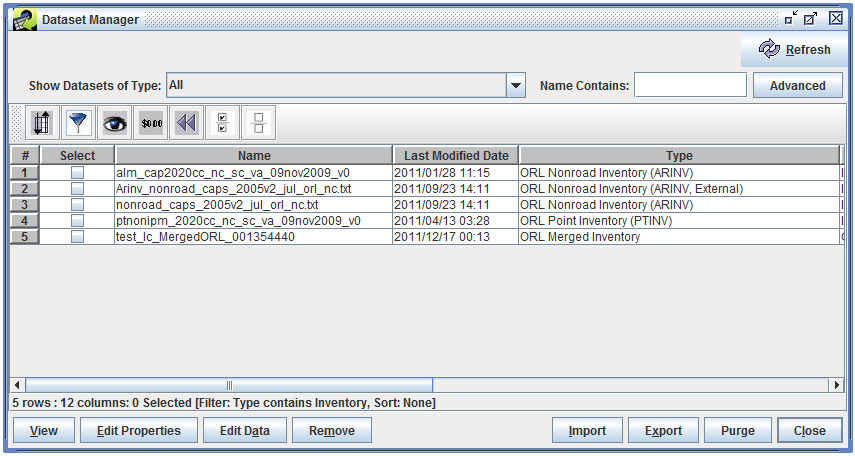
Using filtering allows you to search for datasets using any column shown in the Dataset Manager. Remember that filtering will only apply to the datasets already shown in the table - it doesn’t search the database for additional datasets like the Advanced Dataset Search feature.
To view or edit the properties of a dataset, select the dataset in the Dataset Manager and then click either the View or Edit Properties button at the bottom of the window. The Dataset Properties View or Editor window will be displayed with the Summary tab selected as shown in Figure 3-9. If multiple datasets are selected, separate Dataset Properties windows will be displayed for each selected dataset.
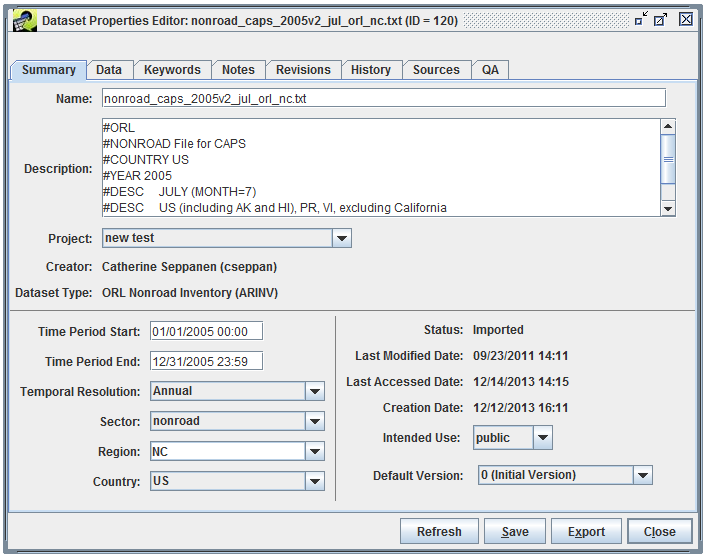
The interface for viewing dataset properties is very similar to the editing interface except that the values are all read-only. In this section, we will show the editing versions of the interface so that all available options are shown. In general, if you don’t need to edit a dataset, it’s better to just view the properties since viewing the dataset doesn’t lock it for editing by another user.
The Dataset Properties window divides its data into several tabs. Table 3-9 gives a brief description of each tab.
| Tab | Description |
|---|---|
| Summary | Shows high-level properties of the dataset |
| Data | Provides access to the actual data stored for the dataset |
| Keywords | Shows additional types of metadata not found on the Summary tab |
| Notes | Shows comments that users have made about the dataset and questions they may have |
| Revisions | Shows the revisions that have been made to the dataset |
| History | Shows how the dataset has been used in the past |
| Sources | Shows where the data came from and where it is stored in the database, if applicable |
| QA | Shows QA steps that have been run using the dataset |
There are several buttons at the bottom of the editor window that appear on all tabs:
The Summary tab of the Dataset Properties Editor (Figure 3-9) displays high level summary information about the Dataset. Many of these properties are shown in the list of datasets displayed by the Dataset Manager and as a result are described in Table 3-6. The additional properties available in the Summary tab are described in Table 3-10.
| Column | Description |
|---|---|
| Description | Descriptive information about the dataset. The contents of this field are initially populated from the full-line comments found in the header and other sections of the file used to create the dataset when it is imported. Users are free to add on to the contents of this field which is written to the top of the resulting file when the data is exported from the EMF. |
| Sector | The emissions sector to which this data applies. |
| Country | The country to which the data applies. |
| Last Accessed Date | The date/time the data was last exported. |
| Creation Date | The date/time the dataset was created. |
| Default Version | Indicates which version of the dataset is considered to be the default. The default version of a dataset is important in that it indicates to other users and to some quality assurance queries the appropriate version of the dataset to be used. |
Values of text fields (boxes with white background) are changed by typing into the fields. Other properties are set by selecting items from pull-down menus.
Some notes about updating the various editable fields follow:
Name: If you change the dataset name, the EMF will verify that your newly selected name is unique within the EMF.
Description: Be careful updating the description if the file will be exported for use in SMOKE. For example, ORL files must start with #ORL or SMOKE will not accept them. Thus, it is safer to add information to the end of the description.
Project: You may select a different project for the dataset by choosing another item from the pull-down menu. If you are an EMF Administrator, you can create a new project by typing a non-existent value into the editable menu.
Region: You can select an existing region by choosing an item from the pull-down menu or you can type a value into the editable menu to add a new region.
Default Version: Only versions of datasets that have been marked as final can be selected as the default version.
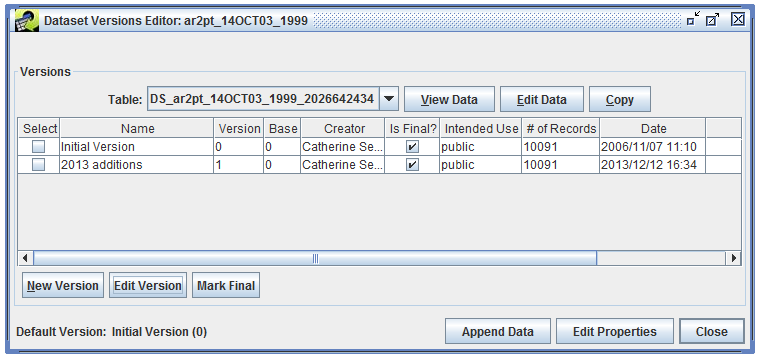
The Data tab of the Dataset Properties Editor (Figure 3-10) provides access to the actual data stored for the dataset. If the dataset has multiple versions, they will be listed in the Versions table.
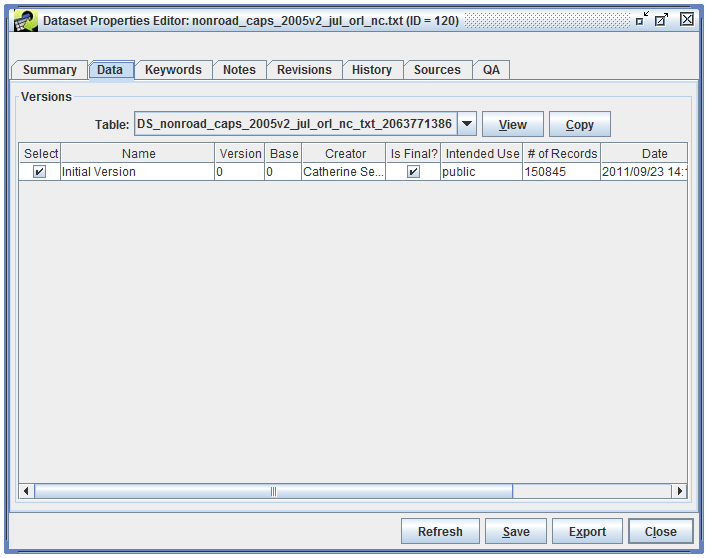
To view the data associated with a particular version, select the version and click the View button. For more information about viewing the raw data, see Section 3.6. The Copy button allows you to copy any version of the data marked as final to a new dataset.
The Keywords tab of the Dataset Properties Editor (Figure 3-11) shows additional types of metadata about the dataset stored as keyword-value pairs.
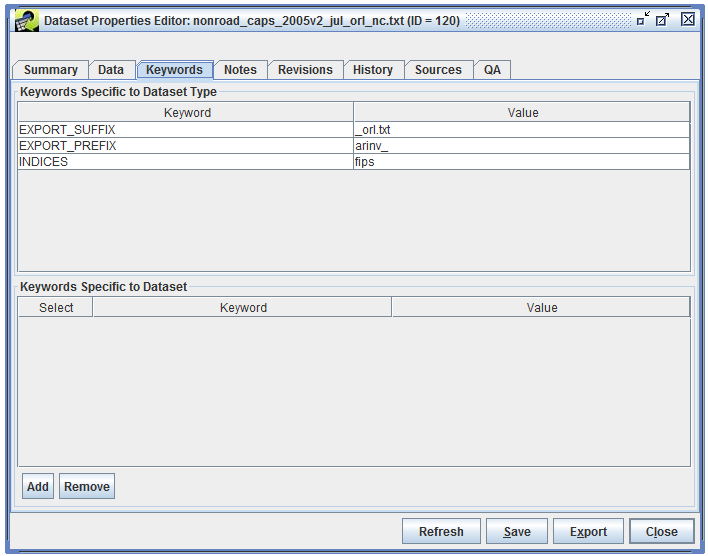
The Keywords Specific to Dataset Type section show keywords associated with the dataset’s type. These keywords are described in Section 3.2.
Additional dataset-specific keywords can be added by clicking the Add button. A new entry will be added to the Keyword Specific to Dataset section of the window. Type the keyword and its value in the Keyword and Value cells.
The Notes tab of the Dataset Properties Editor (Figure 3-12) shows comments that users have made about the dataset and questions they may have. Each note is associated with a particular version of a dataset.
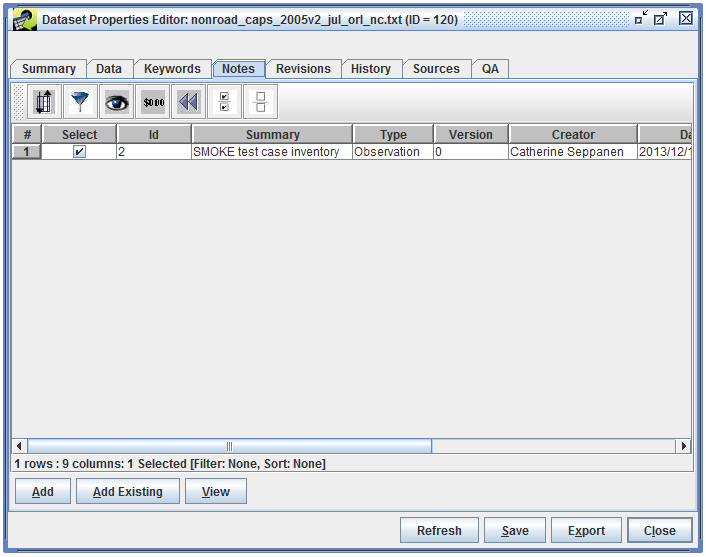
To create a new note about a dataset, click the Add button and the Create New Note dialog will open (Figure 3-13). Notes can reference other notes so that questions can be answered. Click the Set button to display other notes for this dataset and select any referenced notes.
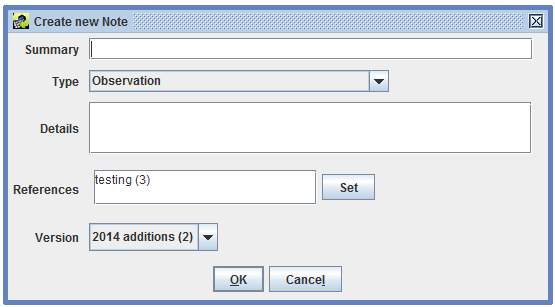
The Add Existing button in the Notes tab opens a dialog to add existing notes to the dataset. This feature is useful if you need to add the same note to a set of files. Add a new note for the first dataset and then for subsequent datasets, use the “Note name contains:” field to search for the newly added note. In the list of matched notes, select the note to add and click the OK button.
The Revisions tab of the Dataset Properties Editor (Figure 3-15) shows revisions that have been made to the data contained in the dataset. See Section 3.7 for more information about editing the raw data.
The History tab of the Dataset Properties Editor (Figure 3-16) shows the export history of the dataset. When the dataset is exported, a history record is automatically created containing the name of the user who exported the data, the version that was exported, the location on the server where the file was exported, and statistics about how many lines were exported and the export time.
The Sources tab of the Dataset Properties Editor (Figure 3-17) shows where the data associated with the dataset came from and where it is stored in the database, if applicable. For datasets where the data is stored in the EMF database, the Table column shows the name of the table in the EMF database and Source lists the original file the data was imported from.
Figure 3-18 shows the Sources tab for a dataset that references external files. In this case, there is no Table column since the data is not stored in the EMF database. The Source column lists the current location of the external file. If the location of the external file changes, you can click the Update button to browse for the file in its new location.
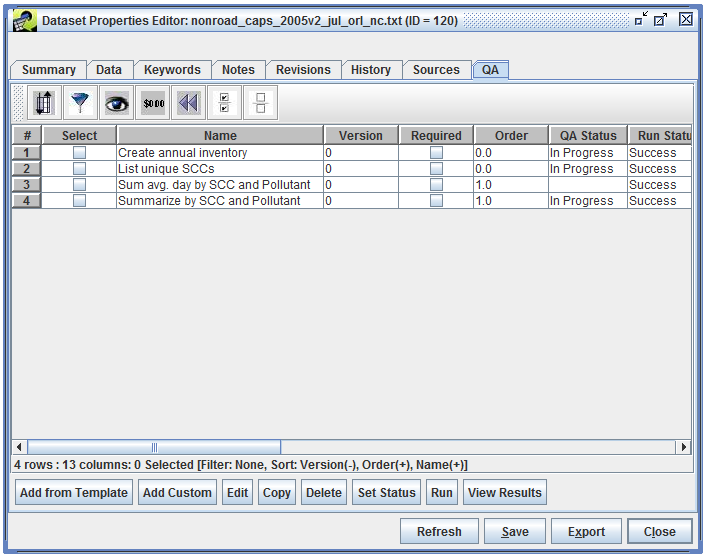
The QA tab of the Dataset Properties Editor (Figure 3-19) shows the QA steps that have been run using the dataset. See Chapter 4. for more information about setting up and running QA steps.
The EMF allows you to view and edit the raw data stored for each dataset. To work with the data, select a dataset from the Dataset Manager and click the Edit Data button to open the Dataset Versions Editor (Figure 3-20). This window shows the same list of versions as the Dataset Properties Data tab (Section 3.5.2).
To view the data, select a version and click the View Data button. The raw data is displayed in the Data Viewer as shown in Figure 3-21.
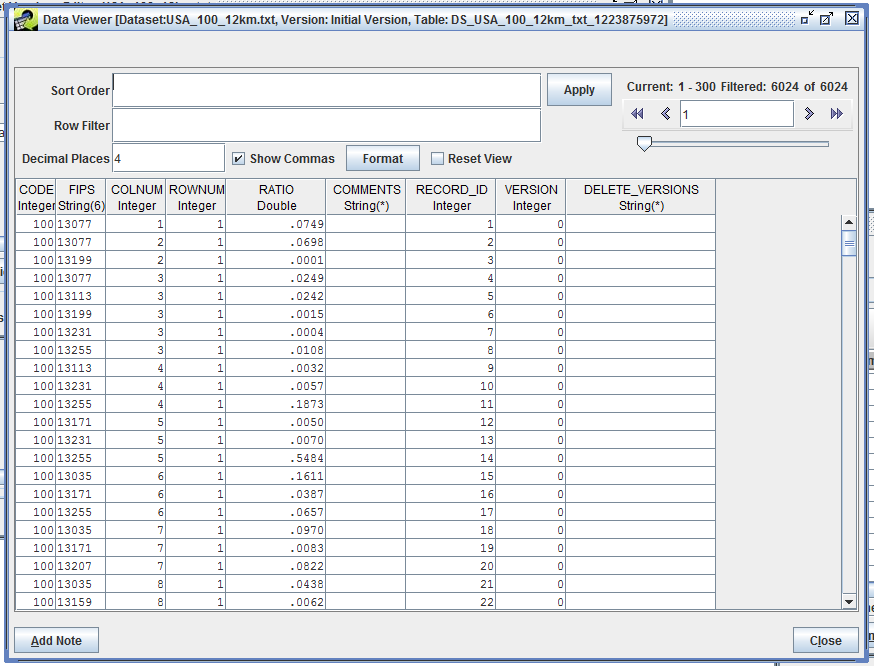
Since the data stored in the EMF may have millions of rows, the client application only transfers a small amount of data (300 rows) from the server to your local machine at a time. The area in the top right corner of the Data Viewer displays information about the currently loaded rows along with controls for paging through the data. The single left and right arrows move through the data one chunk at a time while the double arrows jump to the beginning and end of the data. If you hover your mouse over an arrow, a tooltip will pop up to remind you of its function. The slider allows you to quickly jump to different parts of the data.
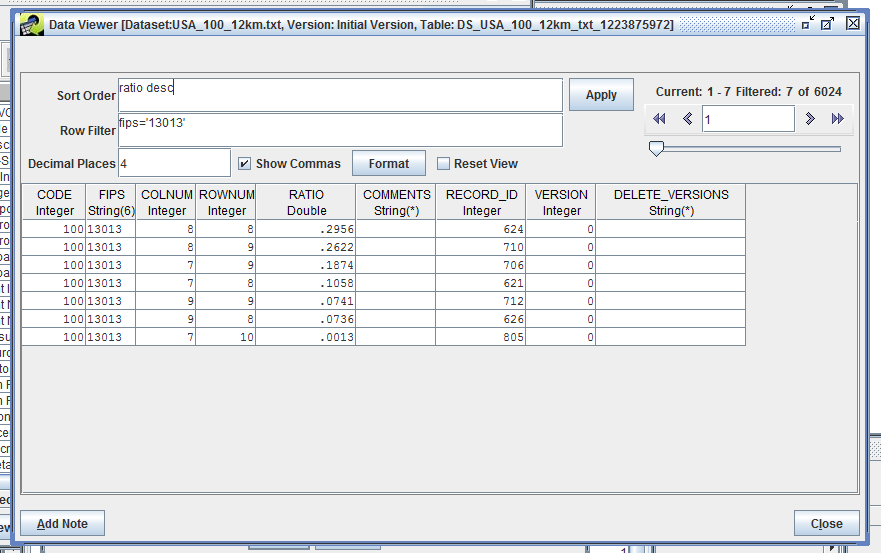
You can control how the data are sorted by entering a comma-separated list of columns in the Sort Order field and then clicking the Apply button. A descending sort can be specified by following the column name with desc.
The Row Filter field allows you to enter criteria and filter the rows that are displayed. The syntax is similar to a SQL WHERE clause. Table 3-11 shows some example filters and the syntax for each.
| Filter Purpose | Row Filter Syntax |
|---|---|
| Filter on a particular set of SCCs | scc like '101%' or scc like '102%' |
| Filter on a particular set of pollutants | poll in ('PM10', 'PM2_5') |
| Filter sources only in NC (State FIPS = 37), SC (45), and VA (51); note that FIPS column format is State + County FIPS code (e.g., 37001) |
substring(FIPS,1,2) in ('37', '45', '51') |
| Filter sources only in CA (06) and include only NOx and VOC pollutants | fips like '06%' and (poll = 'NOX' or poll = 'VOC') |
Figure 3-22 shows the data sorted by the column “ratio” in descending order and filtered to only show rows where the FIPS code is “13013”.
The Row Filter syntax used in the Data Viewer can also be used when exporting datasets to create filtered export files (Section 3.8.1. If you would like to create a new dataset based on a filtered existing dataset, you can export your filtered dataset and then import the resulting file as a new dataset. Section 3.8 describes exporting datasets and Section 3.9 explains how to import datasets.
The EMF does not allow data to be edited after a version has been marked as final. If a dataset doesn’t have a non-final version, first you will need to create a new version. Open the Dataset Versions Editor as shown in Figure 3-20. Click the New Version button to bring up the Create a New Version dialog window like Figure 3-23.
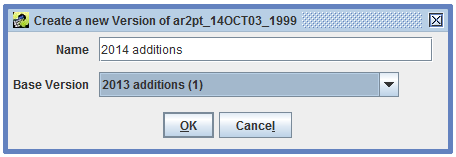
Enter a name for the new version and select the base version. The base version is the starting point for the new version and can only be a version that is marked as final. Click OK to create the new version. The Dataset Versions Editor will show your newly created version (Figure 3-24).
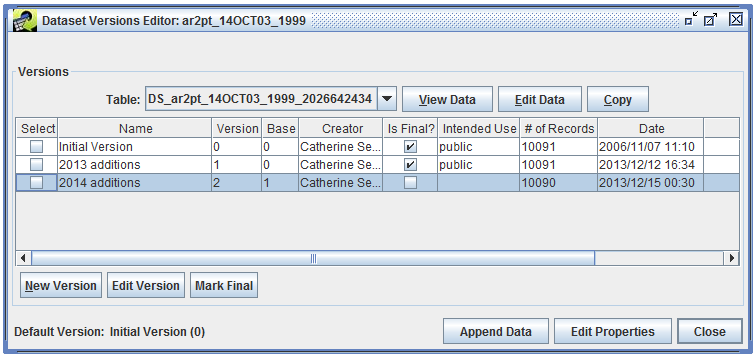
You can now select the non-final version and click the Edit Data button to display the Data Editor as shown in Figure 3-25.
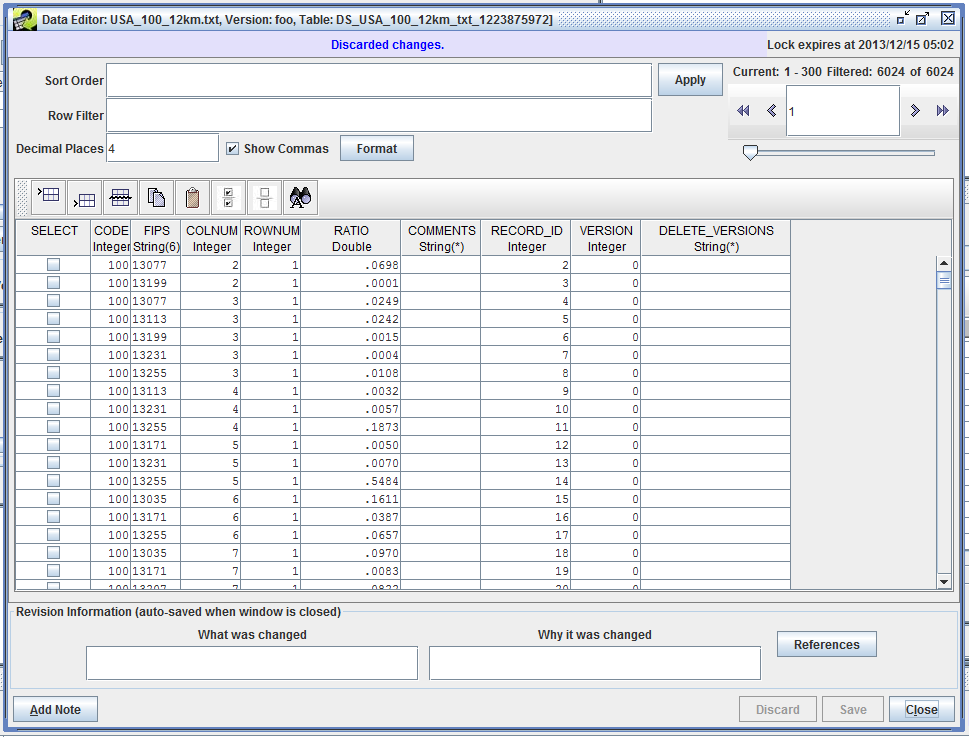
The Data Editor uses the same paging mechanisms, sort, and filter options as the Data Viewer described in Section 3.6. You can double-click a data cell to edit the value. The toolbar shown in Figure 3-26 provides options for adding and deleting rows.

The functions of each toolbar button are described below, listed left to right:
In the Data Editor window, you can undo your changes by clicking the Discard button. Otherwise, click the Save button to save your changes. If you have made changes, you will need to enter Revision Information before the EMF will allow you to close the window. Revisions for a dataset are shown in the Dataset Properties Revisions tab (see Section 3.5.5).
When you export a dataset, the EMF will generate a file containing the data in the format defined by the dataset’s type. To export a dataset, you can either select the dataset in the Dataset Manager window and click the Export button or you can click the Export button in the Dataset Properties window. Either way will open the Export dialog as shown in Figure 3-28. If you have multiple datasets selected in the Dataset Manager when you click the Export button, the Export dialog will list each dataset in the Datasets field.
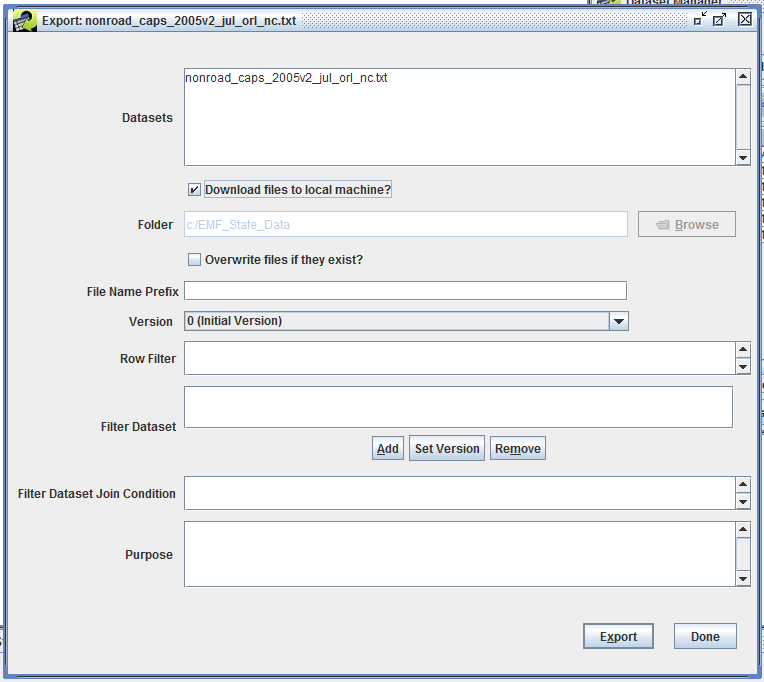
Typically, you will check the Download files to local machine? checkbox. With this option, the EMF will export the dataset to a file on the EMF server and then automatically download it to your local machine. When downloading files to your local machine, the folder input field is not active. The downloaded files will be placed in a temporary directory on your local computer. The EMF property local.temp.dir controls the location of the temporary directory. EMF properties can be edited in the EMFPrefs.txt file. Note that the Overwrite files if they exit? checkbox isn’t functional at this point.
You can enter a prefix to be added to the names of the exported files in the File Name Prefix field. Exported files will be named based on the dataset name and may have prefixes or suffixes attached based on keywords associated with the dataset or dataset type.
If you are exporting a single dataset and that dataset has multiple versions, the Version pull-down menu will allow you to select which version you would like to export. If you are exporting multiple datasets, the default version of each dataset will be exported.
The Row Filter, Filter Dataset, and Filter Dataset Join Condition fields allow for filtering the dataset during export to reduce the total number of rows exported. See Section 3.8.1 for more information about these settings.
Before clicking the Export button, enter a Purpose for your export. This will be logged as part of the history for the dataset. If you do not enter any text in the Purpose field, the fact that you exported the dataset will still be logged as part of the dataset’s history. At this time, history records are only created when the Download files to local machine? checkbox is not checked.
After clicking the Export button, check the Status window to see if any problems arise during the export. If the export succeeds, you will see a status message like
Completed export of nonroad_caps_2005v2_jul_orl_nc.txt to <server directory>/nonroad_caps_2005v2_jul_orl_nc.txt in 2.137 seconds. The file will start downloading momentarily, see the Download Manager for the download status.
You can bring up the Downloads window as shown in Figure 3-29 by opening the Window menu at the top of the EMF main window and selecting Downloads.
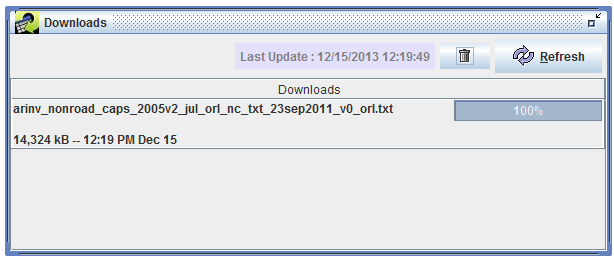
As your file is downloading, the progress bar on the right side of the window will update to show you the progress of the download. Once it reaches 100%, your download is complete. Right click on the filename in the Downloads window and select Open Containing Folder to open the folder where the file was downloaded.
The export filtering options allow you to select and export portions of a dataset based on your matching criteria.
The Row Filter field shown in the Export Dialog in Figure 3-28 uses the same syntax as the Data Viewer window (Section 3.6) and allows you to export only a subset of the data. Example filters are shown in Table 3-11.
Filter Dataset and Filter Dataset Join Condition, also shown in Figure 3-28, allow for advanced filtering of the dataset using an additional dataset. For example, if you are exporting a nonroad inventory, you can choose to only export rows that match a different inventory by FIPS code or SCC. When you click the Add button, the Select Datasets dialog appears as in Figure 3-30.
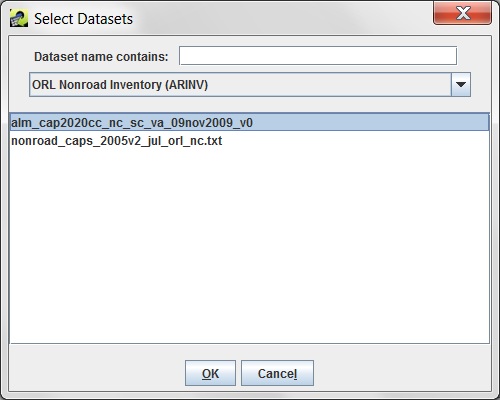
Select the dataset type for the dataset you want to use as a filter from the pull-down menu. You can use the Dataset name contains field to further narrow down the list of matching datasets. Click on the dataset name to select it and then click OK to return to the Export dialog.
The selected dataset is now shown in the Filter Dataset box. If the filter dataset has multiple versions, click the Set Version button to select which version to use for filtering. You can remove the filter dataset by clicking the Remove button.
Next, you will enter the criteria to use for filtering in the Filter Dataset Join Condition textbox. The syntax is similar to a SQL JOIN condition where the left hand side corresponds to the dataset being exported and the right hand side corresponds to the filter dataset. You will need to know the column names you want to use for each dataset.
| Type of Filter | Filter Dataset Join Condition |
|---|---|
| Export records where the FIPS, SCC, and plant IDs are the same in both datasets; both datasets have the same column names |
fips=fips scc=scc plantid=plantid |
| Export records where the SCC, state codes, and pollutants are the same in both datasets; the column names differ between the datasets |
scc=scc_code substring(fips,1,2)=state_cd poll=poll_code |
Once your filter conditions are set up, click the Export button to begin the export. Only records that match all of the filter conditions will be exported. Status messages in the Status window will contain additional information about your filter. If no records match your filter condition, the export will fail and you will see a status message like:
Export failure. ERROR: nonroad_caps_2005v2_jul_orl_nc.txt will not be exported because no records satisfied the filter
If the export succeeds, the status message will include a count of the number of records in the database and the number of records exported:
No. of records in database: 150845; Exported: 26011
Importing a dataset is the process where the EMF reads a data file or set of data files from disk, stores the data in the database (for internal dataset types), and creates metadata about the dataset. To import a dataset, start by clicking the Import button in the bottom right corner of the Dataset Manager window (Figure 3-4). The Import Datasets dialog will be displayed as shown in Figure 3-31. You can also bring up the Import Datasets dialog from the main EMF File menu, then select Import.
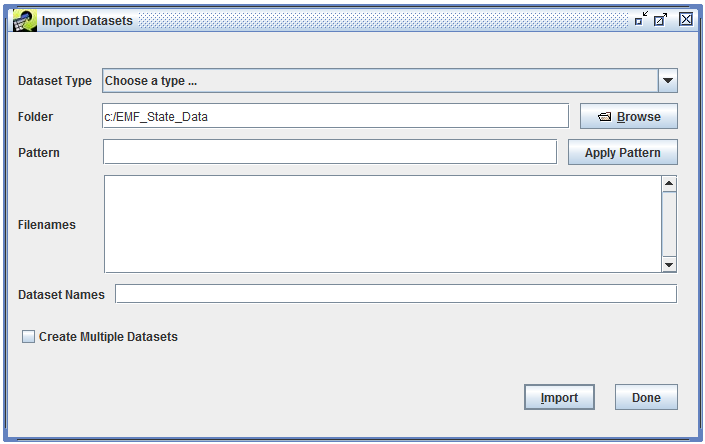
An advantage to opening the Import Datasets dialog from the Dataset Manager as opposed to using the File menu is that if you have a dataset type selected in the Dataset Manager Show Datasets of Type pull-down menu, then that dataset type will automatically be selected for you in the Import Datasets dialog.
In the Import Datasets dialog, first use the Dataset Type pull-down menu to select the dataset type corresponding to the file you want to import. For example, if your data file is a annual point-source emissions inventory in Flat File 2010 (FF10) format, you would select the dataset type “Flat File 2010 Point”. Section 3.2.1 lists commonly used dataset types. Keep in mind that your EMF installation may have different dataset types available.
Most dataset types specify that datasets of that type will use data from a single file. For example, for the Flat File 2010 Point dataset type, you will need to select exactly one file to import per dataset. Other dataset types can require or optionally allow multiple files to import into a single dataset. Some dataset types can use a large number of files like the Day-Specific Point Inventory (External Multifile) dataset type which allows up to 366 files for a single dataset. Thus, the Import Datasets dialog will allow you to select multiple files during the import process and has tools for easily matching multiple files.
Next, select the folder where the data files to import are located on the EMF server. You can either type or paste (using Ctrl-V) the folder name into the field labeled Folder, or you can click the Browse button to open the remote file browser as shown in Figure 3-32. Important! To import data files, the files must be accessible by the machine that the EMF server is running on. If the data files are on your local machine, you will need to transfer them to the EMF server before you can import them.
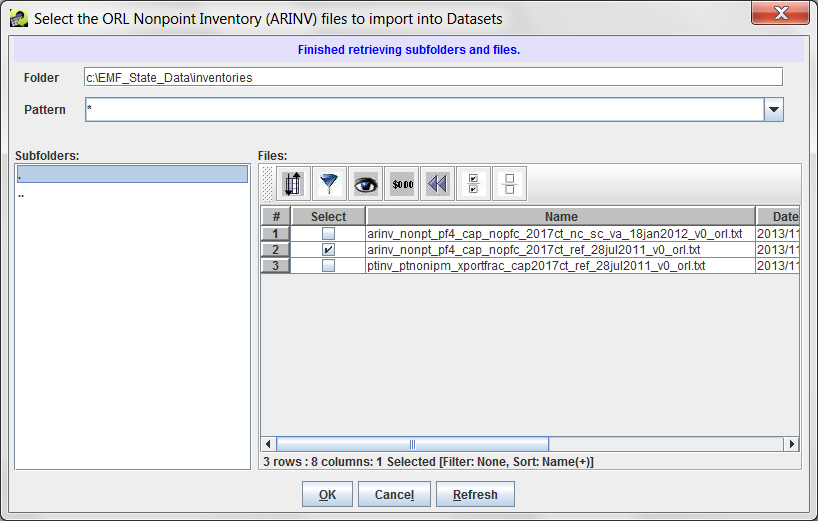
To use the remote file browser, you can navigate from your starting folder to the file by either typing or pasting a directory name into the Folder field or by using the Subfolders list on the left side of the window. In the Subfolders list, double-click on a folder’s name to go into that folder. If you need to go up a level, double-click the .. entry.
Once you reach the folder that contains your data files, select the files to import by clicking the checkbox next to each file’s name in the Files section of the browser. The Files section uses the Sort-Filter-Select Table described in Section 2.6.6 to list the files. If you have a large number of files in the directory, you can use the sorting and filtering options of the Sort-Filter-Select Table to help find the files you need.
You can also use the Pattern field in the remote file browser to only show files matching the entered pattern. By default the pattern is just the wildcard character * to match all files. Entering a pattern like arinv*2002*txt will match filenames that start with “arinv”, have “2002” somewhere in the filename, and then end with “txt”.
Once you’ve selected the files to import, click OK to save your selections and return to the Import Datasets dialog. The files you selected will be listed in the Filenames textbox in the Import Datasets dialog as shown in Figure 3-33. If you selected a single file, the Dataset Names field will contain the filename of the selected file as the default dataset name.
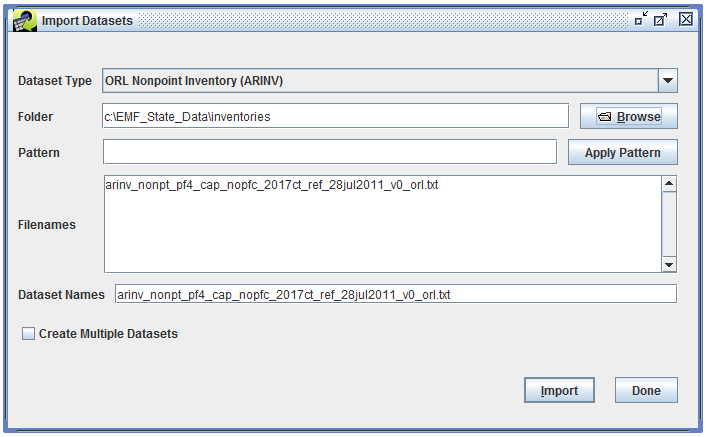
Update the Dataset Names field with your desired name for the dataset. If the dataset type has EXPORT_PREFIX or EXPORT_SUFFIX keywords assigned, these values will be automatically stripped from the dataset name. For example, the ORL Nonpoint Inventory (ARINV) dataset type defines EXPORT_PREFIX as “arinv_” and EXPORT_SUFFIX as “_orl.txt”. Suppose you select an ORL nonpoint inventory file named “arinv_nonpt_pf4_cap_nopfc_2017ct_ref_orl.txt” to import. By default the Dataset Names field in the Import Datasets dialog will be populated with “arinv_nonpt_pf4_cap_nopfc_2017ct_ref_orl.txt” (the filename). On import, the EMF will automatically convert the dataset name to “nonpt_pf4_cap_nopfc_2017ct_ref” removing the EXPORT_PREFIX and EXPORT_SUFFIX.
Click the Import button to start the dataset import. If there are any problems with your import settings, you’ll see a red error message displayed at the top of the Import Datasets window. Table 3-13 shows some example error messages and suggested solutions.
| Example Error Message | Solution |
|---|---|
| A Dataset Type should be selected | Select a dataset type from the Dataset Type pull-down menu. |
| A Filename should be specified | Select a file to import. |
| A Dataset Name should be specified | Enter a dataset name in the Dataset Names textbox. |
| The ORL Nonpoint Inventory (ARINV) importer can use at most 1 files | You selected too many files to import for the dataset type. Select the correct number of files for the dataset type. If you want to import multiple files of the same dataset type, see Section 3.9.1. |
| The NIF3.0 Nonpoint Inventory importer requires at least 2 files | You didn’t select enough files to import for the dataset type. Select the correct number of files for the dataset type. |
| Dataset name nonpt_pf4_cap_nopfc_2017ct_ref has been used. | Each dataset in the EMF needs a unique dataset name. Update the dataset name to be unique. Remember that the EMF will automatically remove the EXPORT_PREFIX and EXPORT_SUFFIX if defined for the dataset type. |
If your import settings are good, you will see the message “Started import. Please monitor the Status window to track your import request.” displayed at the top of the Import Datasets window as shown in Figure 3-34.
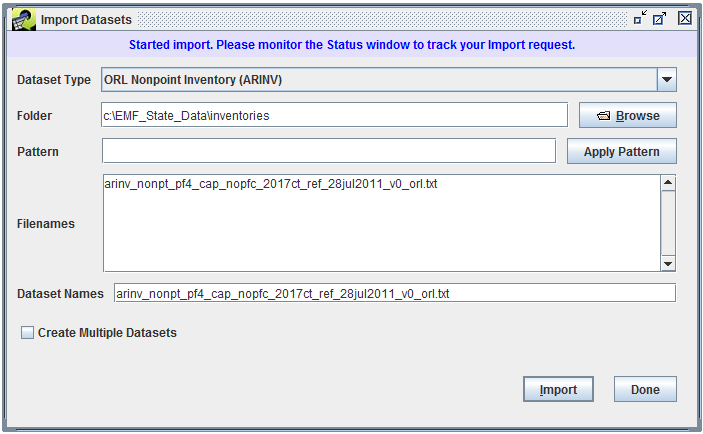
In the Status window, you will see a status message like:
Started import of nonpt_pf4_cap_nopfc_2017ct_nc_sc_va_18jan2012_v0 [ORL Nonpoint Inventory (ARINV)] from arinv_nonpt_pf4_cap_nopfc_2017ct_nc_sc_va_18jan2012_v0.txt
Depending on the size of your file, the import can take a while to complete. Once the import is complete, you will see a status message like:
Completed import of nonpt_pf4_cap_nopfc_2017ct_nc_sc_va_18jan2012_v0 [ORL Nonpoint Inventory (ARINV)] in 57.6 seconds from arinv_nonpt_pf4_cap_nopfc_2017ct_nc_sc_va_18jan2012_v0.txt
To see your newly imported dataset, open the Dataset Manager window and find your dataset by dataset type or using the Advanced search. You may need to click the Refresh button in the upper right corner of the Dataset Manager window to get the latest dataset information from the EMF server.
You can use the Import Datasets window to import multiple datasets of the same type at once. In the remote file browser (shown in Figure 3-32), select all the files you would like to import and click OK. In the Import Datasets window, check the checkbox Create Multiple Datasets as shown in Figure 3-35. The Dataset Names textbox goes away.
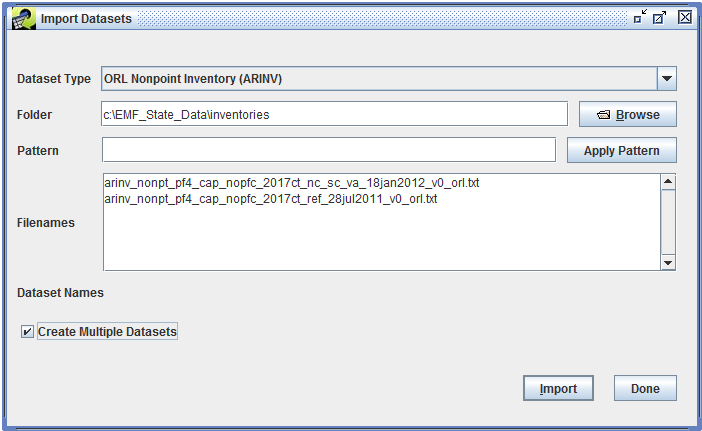
For each dataset, the EMF will automatically name the dataset using the corresponding filename. If the keywords EXPORT_PREFIX or EXPORT_SUFFIX are defined for the dataset type, the keyword values will be stripped from the filenames when generating the dataset names. If these keywords are not defined for the dataset type, then the dataset name will be identical to the filename.
Click the Import button to start importing the datasets. The Status window will display Started and Completed status messages for each dataset as it is imported.
Use a consistent naming scheme that works for your group. If you have a naming system already in place, continue using it in the EMF. You can enter your own dataset names when importing files and also edit a dataset’s name if you have the appropriate privileges. The EMF will automatically make sure that the dataset names are unique.
Avoid dates in your dataset names. When a dataset is exported, the EMF will automatically include the dataset’s last modified date in name of the exported file.
For monthly inventory files, include the three character month abbreviation in the dataset name (i.e. “jan”, “feb”, “mar”, etc.). These names are used in certain QA steps.
Enter as much metadata about each dataset as possible, for example the temporal resolution of the data, time period covered, and region. These fields can be used when filtering datasets in the Dataset Manager window.
Use the Project field to group sets of files together. EMF Administrators can create new project names to aid in organizing files.
Try out the different options for finding datasets in the Dataset Manager (Section 3.4) to see what works best for your workflow. You may find that the Advanced Dataset Search fits what you need to do or perhaps filtering the dataset list is more useful.
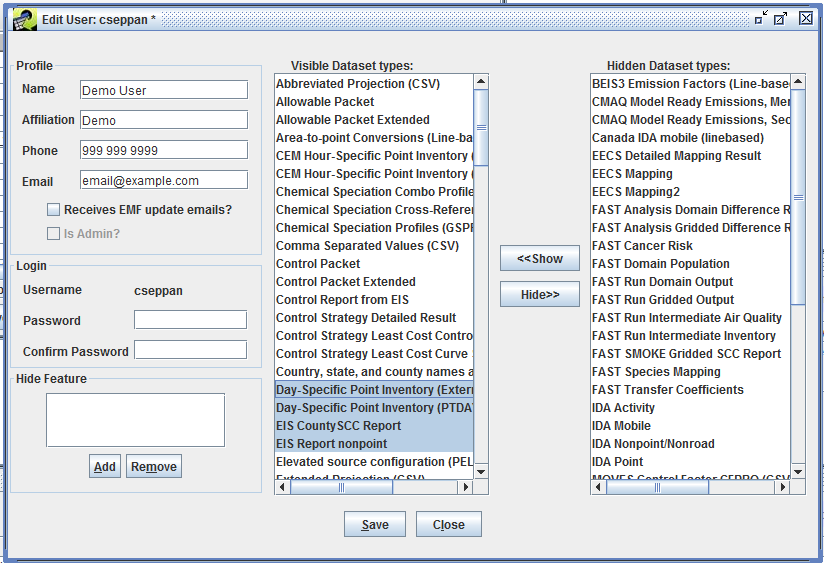
Hide dataset types that you don’t use. Each user can control the list of dataset types that the EMF client will use when displaying dataset type pull-down menus (like the Show Datasets of Type pull-down menu in the Manage Datasets window). From the Manage menu, select My Profile to show the Edit User window (Figure 3-36). In this window, you can select dataset types from the Visible Dataset Types list, then click the Hide button to move the selected types to the Hidden Dataset Types list. Selecting items in the hidden list and clicking the Show button will move the selected types back to the visible list. Click the Save button to save your changes. Note that if the Dataset Manager window is open, you’ll need to close it and open it again for the list of dataset types to refresh.
The EMF allows you to perform various types of analyses on a dataset or set of datasets. For example, you can summarize the data by different aspects such as geographic region like county or state, SCC code, pollutant, or plant ID. You can also compare or sum multiple datasets. Within the EMF, running an analysis like this is called a QA step.
A dataset can have many QA steps associated with it. To view a dataset’s QA steps, first select the dataset in the Dataset Manager and click the Edit Properties button. Switch to the QA tab to see the list of QA steps as in Figure 4-1.
At the bottom of the window you will see a row of buttons for interacting with the QA steps starting with Add from Template, Add Custom, Edit, etc. If you do not see these buttons, make sure that you are editing the dataset’s properties and not just viewing them.
Each dataset type can have predefined QA steps called QA Step Templates. QA step templates can be added to a dataset type and configured by EMF Administrators using the Dataset Type Manager (see Section 3.2). QA step templates are easy to run for a dataset because they’ve already been configured.
To see a list of available QA step templates for your dataset, open your dataset’s QA tab in the Dataset Properties Editor (Figure 4-1). Click the Add from Template button to open the Add QA Steps dialog. Figure 4-2 shows the available QA step templates for an ORL Nonroad Inventory.
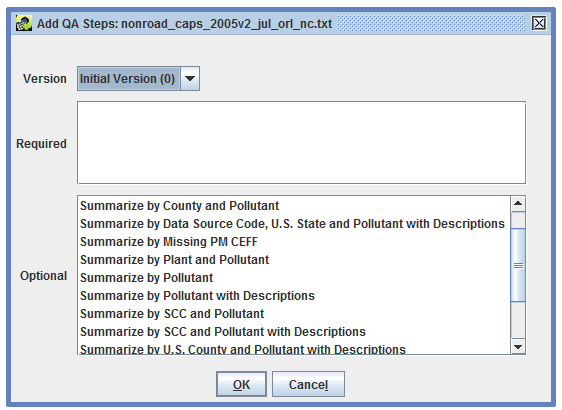
The ORL Nonroad Inventory has various QA step templates for generating different summaries of the inventory.
Summaries “with Descriptions” include more information than those without. For example, the results of the “Summarize by SCC and Pollutant with Descriptions” QA step will include the descriptions of the SCCs and pollutants. Because these summaries with descriptions need to retrieve data from additional tables, they are a bit slower to generate compared to summaries without descriptions.
Select a summary of interest (for example, Summarize by County and Pollutant) by clicking the QA step name. If your dataset has more than one version, you can choose which version to summarize using the Version pull-down menu at the top of the window. Click OK to add the QA step to the dataset.
The newly added QA step is now shown in the list of QA steps for the dataset (Figure 4-3).
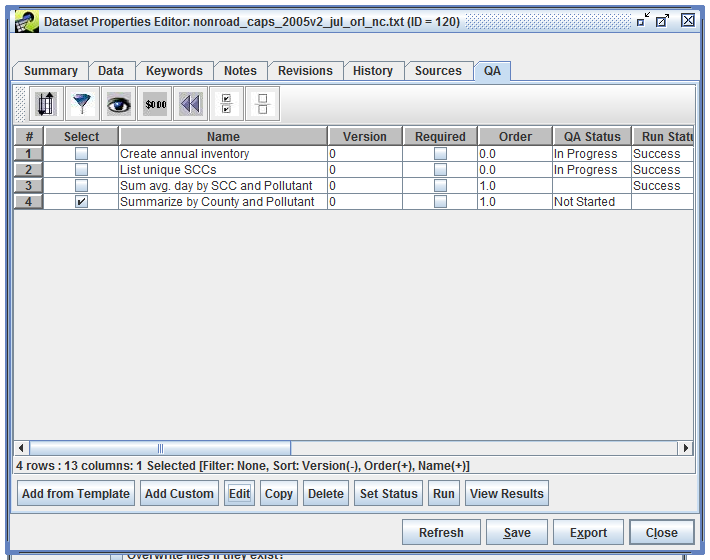
To see the details of the QA step, select the step and click the Edit button. This brings up the Edit QA Step window like Figure 4-4.
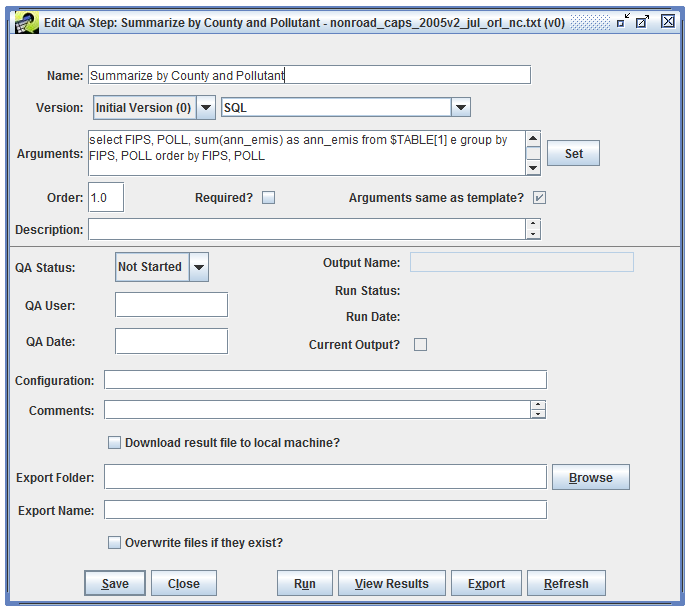
The QA step name is shown at the top of the window. This name was automatically set by the QA step template. You can edit this name if needed to distinguish this step from other QA steps.
The Version pull-down menu shows which version of the data this QA step will run on.
The pull-down menu to the right of the Version setting indicates what type of program will be used for this QA step. In this case, the program type is “SQL” indicating that the results of this QA step will be generated using a SQL query. Most of the summary QA steps are generated using SQL queries. The EMF allows other types of programs to be run as QA steps including Python scripts and various built-in analyses like converting average-day emissions to an annual inventory.
The Arguments textbox shows the arguments used by the QA step program. In this case, the QA step is a SQL query and the Arguments field shows the query that will be run. The special SQL syntax used for QA steps is discussed in Section 4.10.
Other items of interest in the Edit QA Step window include the description and comment textboxes where you can enter a description of your QA step and any comments you have about running the step.
The QA Status field shows the overall status of the QA step. Right now the step is listed as “Not Started” because it hasn’t been run yet. Once the step has been run, the status will automatically change to “In Progress”. After you’ve reviewed the results, you can mark the step as “Complete” for future reference.
The Edit QA Step window also includes options for exporting the results of a QA step to a file. This is described in Section 4.5.
At this point, the next step is to actually run the QA step as described in Section 4.4.
In addition to using QA steps from templates, you can define your own custom QA steps. From the QA tab of the Dataset Properties Editor (Figure 4-1), click the Add Custom button to bring up the Add Custom QA Step dialog as shown in Figure 4-5.
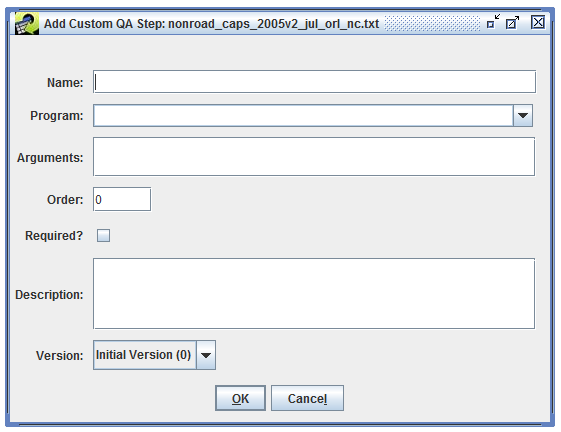
In this dialog, you can configure your custom QA step by entering its name, the program to use, and the program’s arguments.
Creating a custom QA step from scratch is an advanced feature. Oftentimes, you can start by copying an existing step and tweaking it through the Edit QA Step interface.
Section 4.7 shows how to create a custom QA step that uses the built-in QA program “Average day to Annual Inventory” to calculate annual emissions from average-day emissions. Section 4.8 demonstrates using the Compare Datasets QA program to compare two inventories. Section 4.9 gives an example of creating a custom QA step based on a SQL query from an existing QA step.
To run a QA step, open the QA tab of the Dataset Properties Editor and select the QA step you want to run as shown in Figure 4-6.
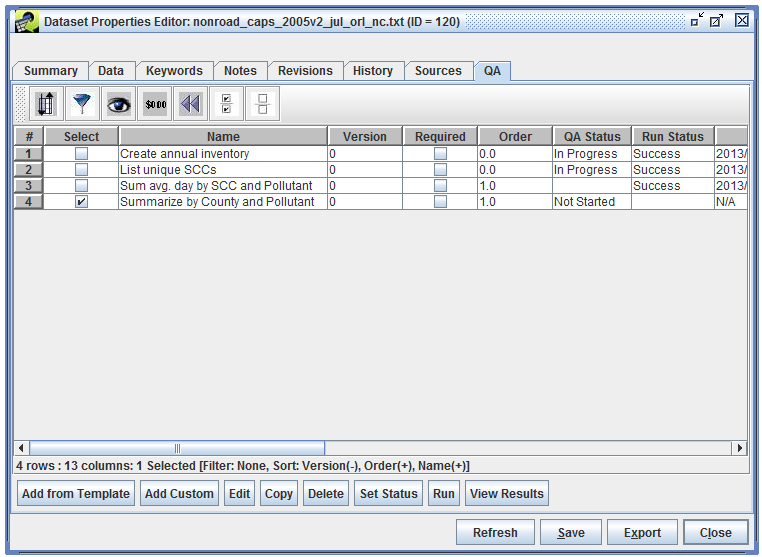
Click the Run button at the bottom of the window to run the QA step. You can also run a QA step from the Edit QA Step window. The Status window will display messages when the QA step begins running and when it completes:
Started running QA step ‘Summarize by County and Pollutant’ for Version ‘Initial Version’ of Dataset ‘nonroad_caps_2005v2_jul_orl_nc.txt’
Completed running QA step ‘Summarize by County and Pollutant’ for Version ‘Initial Version’ of Dataset ‘nonroad_caps_2005v2_jul_orl_nc.txt’
In the QA tab, click the Refresh button to update the table of QA steps as shown in Figure 4-7.
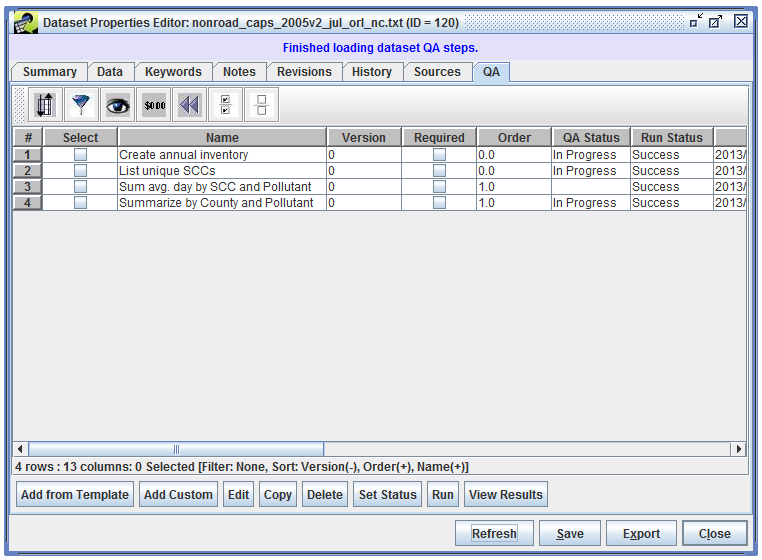
The overall QA step status (the QA Status column) has changed from “Not Started” to “In Progress” and the Run Status is now “Success”. The list of QA steps also shows the time the QA step was run in the When column.
To view the results of the QA step, select the step in the QA tab and click the View Results button. A dialog like Figure 4-8 will pop-up asking how many records of the results you would like to preview.
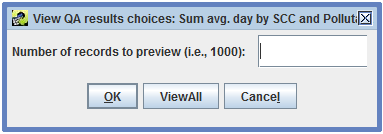
Enter the number of records to view or click the View All button to see all records. The View QA Step Results window will display the results of the QA step as shown in Figure 4-9.
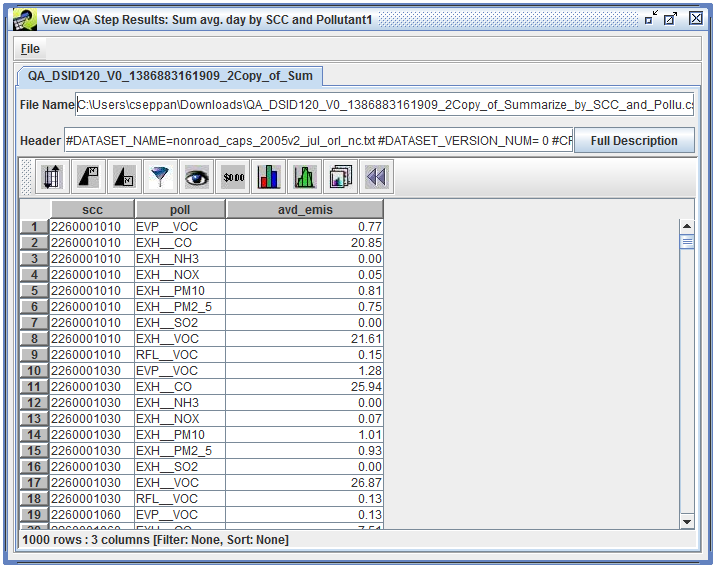
In addition to viewing the results of a QA step in the EMF client application, you can export the results as a comma-separated values (CSV) file. CSV files can be directly opened by Microsoft Excel or other spreadsheet programs to make charts or for further analysis.
To export the results of a QA step, select the QA step of interest in the QA tab of the Dataset Properties Editor. Then click the Edit button to bring up the Edit QA Step window as shown in Figure 4-10.
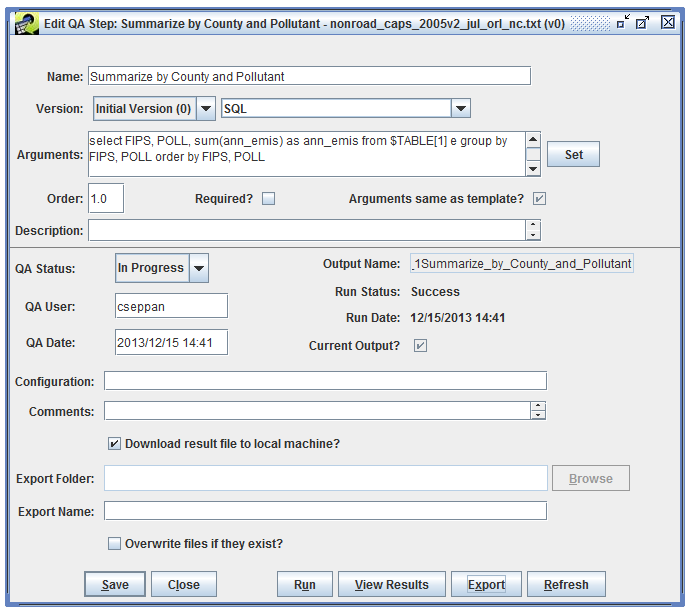
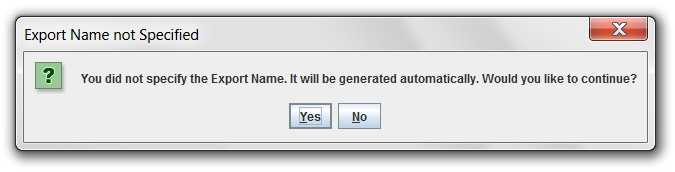
Typically, you will want to check the Download result file to local machine? checkbox so the exported file will automatically be downloaded to your local machine. You can type in a name for the exported file in the Export Name field. Then click the Export button. If you did not enter an Export Name, the application will confirm that you want to use an auto-generated name with the dialog shown in Figure 4-11.
Next, you’ll see the Export QA Step Results customization window (Figure 4-12).
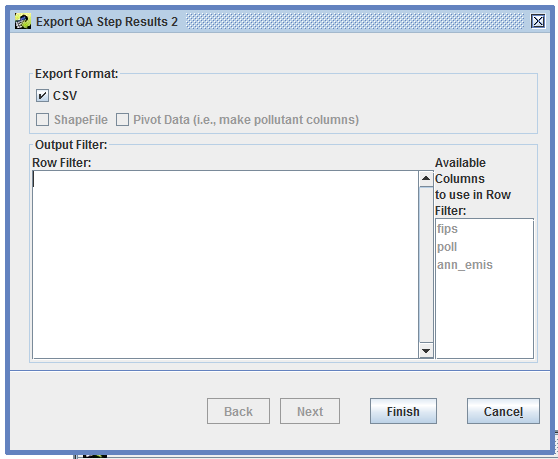
The Row Filter textbox allows you to limit which rows of the QA step results to include in the exported file. Table 3-11 provides some examples of the syntax used by the row filter. Available Columns lists the column names from the results that could be used in a row filter. In Figure 4-12, the columns fips, poll, and ann_emis are available. To export only the results for counties in North Carolina (state FIPS code = 37), the row filter would be fips like '37%'.
Click the Finish button to start the export. At the top of the Edit QA Step window, you’ll see the message “Started Export. Please monitor the Status window to track your export request.” like Figure 4-13
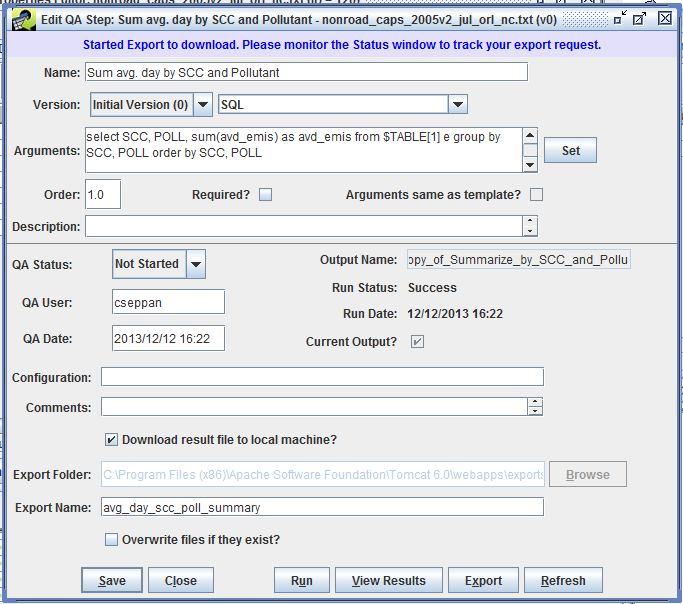
Once your export is complete, you will see a message in the Status window like
Completed exporting QA step ‘Summarize by SCC and Pollutant’ for Version ‘Initial Version’ of Dataset ‘nonpt_pf4_cap_nopfc_2017ct_nc_sc_va’ to <server directory>avg_day_scc_poll_summary.csv. The file will start downloading momentarily, see the Download Manager for the download status.
You can bring up the Downloads window as shown in Figure 4-14 by opening the Window menu at the top of the EMF main window and selecting Downloads.
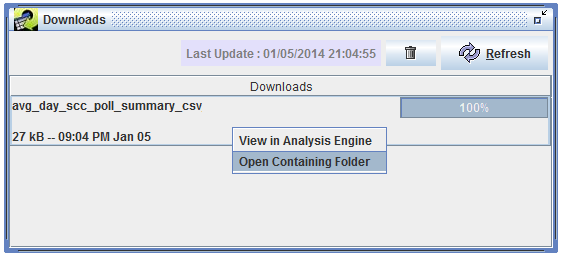
As your file is downloading, the progress bar on the right side of the window will update to show you the progress of the download. Once it reaches 100%, your download is complete. Right click on the filename in the Downloads window and select Open Containing Folder to open the folder where the file was downloaded.
If you have Microsoft Excel or another spreadsheet program installed, you can double-click the downloaded CSV file to open it.
QA step results that include latitude and longitude information can be mapped with geographic information systems (GIS), mapping tools, and Google Earth. Many summaries that have “with Descriptions” in their names include latitude and longitude values. For plant-level summaries, the latitude and longitude in the output are the average of all the values for the specific combination of FIPS and plant ID. For county- and state-level summaries, the latitude and longitude are the centroid values specified in the “fips” table of the EMF reference schema.
To export a KMZ file that can be loaded into Google Earth, you will first need to view the results of the QA step. You can view a QA step’s results by either selecting the QA step in the QA tab of the Dataset Properties Editor (see Figure 4-1) and then clicking the View Results button, or you can click View Results from the Edit QA Step window. Figure 4-15 shows the View QA Step Results window for a summary by county and pollutant with descriptions. The summary includes latitude and longitude values for each county.
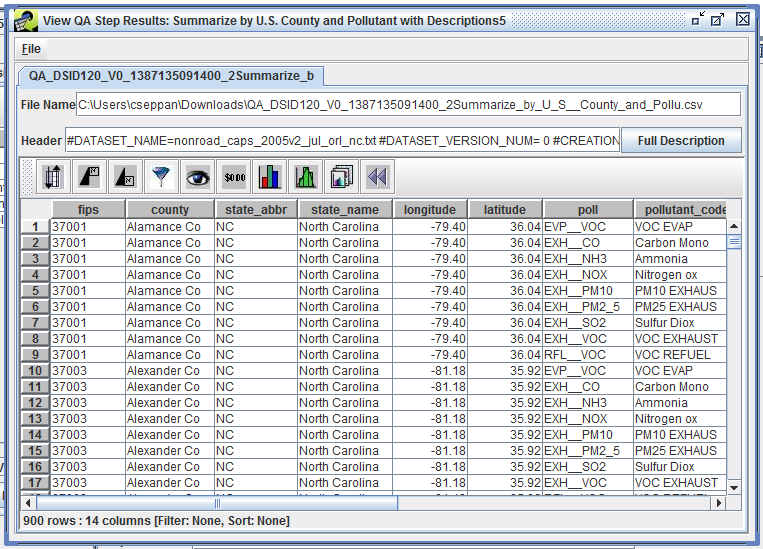
From the File menu in the top left corner of the View QA Step Results window, select Google Earth. Make sure to look at the File menu for the View QA Step Results window, not the main EMF application. The Create Google Earth file window will be displayed as shown in Figure 4-16.
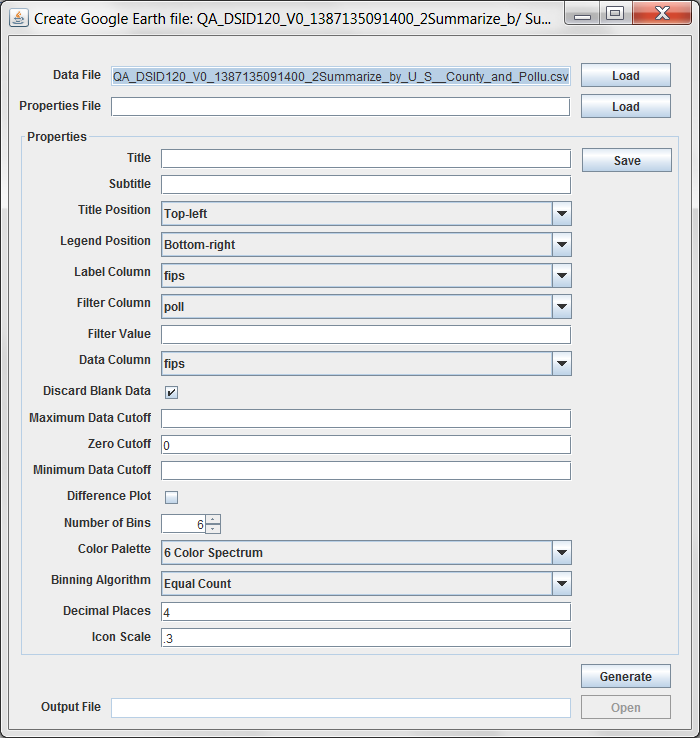
In the Create Google Earth file window, the Label Column pull-down menu allows you to select which column will be used to label the points in the KMZ file. This label will appear when you mouse over a point in Google Earth. For a plant summary, this would typically be “plant_name”; county or state summaries would use “county” or “state_name” respectively.
If your summary has data for multiple pollutants, you will often want to specify a filter so that data for only one pollutant is included in the KMZ file. To do this, specify a Filter Column (e.g. “poll”) and then type in a Filter Value (e.g. “EVP__VOC”).
The Data Column pull-down menu specifies the column to use for the value displayed when you mouse over a point in Google Earth such as annual emissions (“ann_emis”). The mouse over information will have the form: <value from Label Column> : <value from Data Column>.
The Maximum Data Cutoff and Minimum Data Cutoff fields allow you to exclude data points above or below certain thresholds.
If you want to control the size of the points, you can adjust the value of the Icon Scale setting between 0 and 1. The default setting is 0.3; values smaller than 0.3 result in smaller circles and values larger than 0.3 will result in larger circles.
Tooltips are available for all of the settings in the Create Google Earth file window by mousing over each field.
Once you have specified your settings, click the Generate button to create the KMZ file. The location of the generated file is shown in the Output File field. If your computer has Google Earth installed, you can click the Open button to open the file in Google Earth.
If you find that you need to repeatedly create similar KMZ files, you can save your settings to a file by clicking the Save button. The next time you need to generate a Google Earth file, click the Load button next to the Properties File field to load your saved settings.
In addition to analyzing individual datasets, the EMF can run QA steps that use multiple datasets. In this section, we’ll show how to create a custom QA step that calculates an annual inventory from 12 month-specific average-day emissions inventories.
To get started, we’ll need to select a dataset to associate the QA step with. As a best practice, add the QA step to the January-specific dataset in the set of 12 month-specific files. This isn’t required by the EMF but it can make finding multi-file QA steps easier later on. If you have more than 12 month-specific files to use (e.g. 12 non-California inventories and 12 California inventories), add the QA step to the “main” January inventory file (e.g. the non-California dataset).
After determining which dataset to add the QA step to, create a new custom QA step as described in Section 4.3. Figure 4-17 shows the Add Custom QA Step dialog. We’ve entered a name for the step and used the Program pull-down menu to select “Average day to Annual Inventory”.
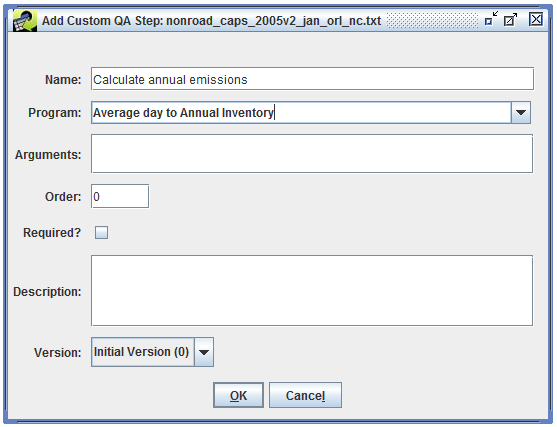
“Average day to Annual Inventory” is a QA program built into the EMF that takes a set of average-day emissions inventories as input and outputs an annual inventory by calculating monthly total emissions and summing all months. Click the OK button in the Add Custom QA Step dialog to save the new QA step. We’ll enter the QA program arguments in a minute. Back in the QA tab of the Dataset Properties Editor, select the newly created QA step and click Edit to open the Edit QA Step window shown in Figure 4-18.
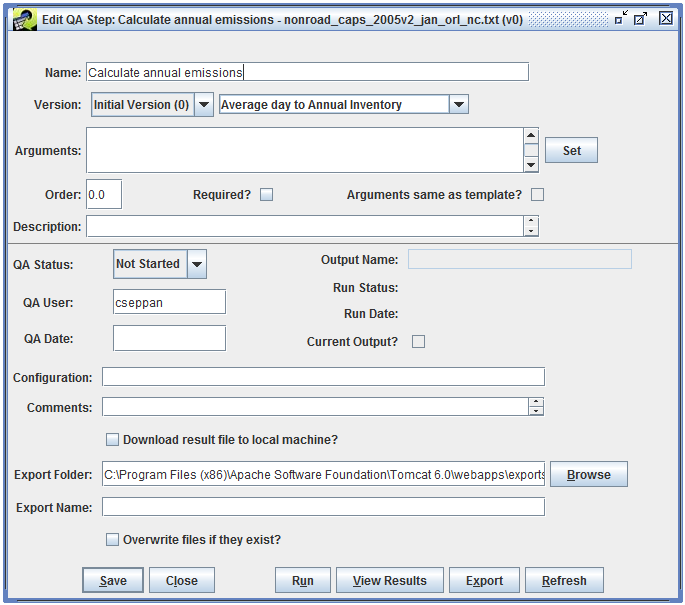
We need to define the arguments that will be sent to the QA program that this QA step will run. The QA program is “Average day to Annual Inventory” so the arguments will be a list of month-specific inventories. Click the Set button to the right of the Arguments box to open the Set Inventories dialog as shown in Figure 4-19.
The Set Inventories dialog is specific to the “Average day to Annual Inventory” QA program. Other QA programs have different dialogs for setting up their arguments. The January inventory that we added the QA step to is already listed. We need to add the other 11 month-specific inventory files. Click the Add button to open the Select Datasets dialog shown in Figure 4-20.
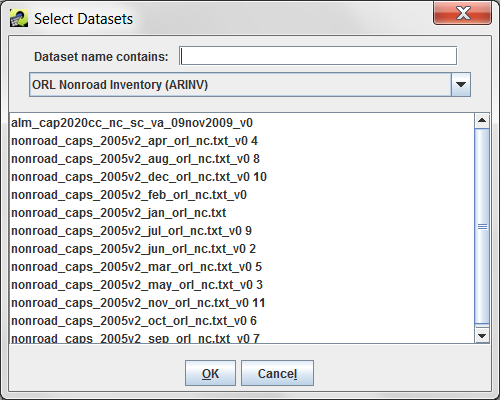
In the Select Datasets dialog, the dataset type is automatically set to ORL Nonroad Inventory (ARINV) matching our January inventory. The other ORL nonroad inventory datasets are shown in a list. We can use the Dataset name contains: field to enter a search term to narrow the list. We’re using 2005 inventories so we’ll enter 2005 as our search term to match only those datasets whose name contains “2005”. Then we’ll select all the inventories in the list as shown in Figure 4-21.
Select inventories by clicking on the dataset name. You can select a range of datasets by clicking on the first dataset you want to select in the list. Then hold down the Shift key while clicking on the last dataset you want to select. All of the datasets in between will also be selected. If you hold down the Ctrl key while clicking on datasets, you can select multiple items from the list that aren’t next to each other.
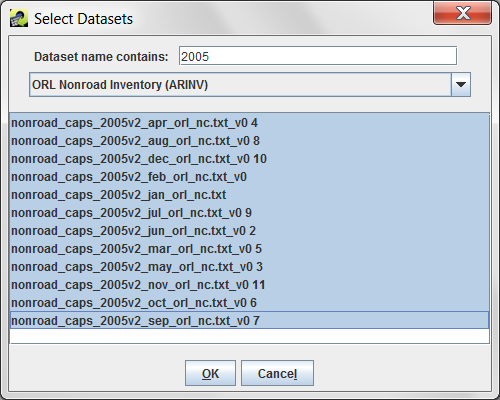
Click the OK button in the Select Datasets dialog to save the selected inventories and return to the Set Inventories dialog. As shown in Figure 4-22, the list of emission inventories now contains all 12 month-specific datasets.
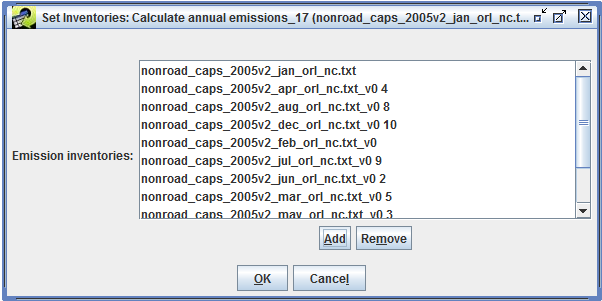
Click the OK button in the Set Inventories dialog to return to the Edit QA Step window shown in Figure 4-23. The Arguments textbox now lists the 12 month-specific inventories and the flag (-inventories) needed for the “Average day to Annual Inventory” QA program.
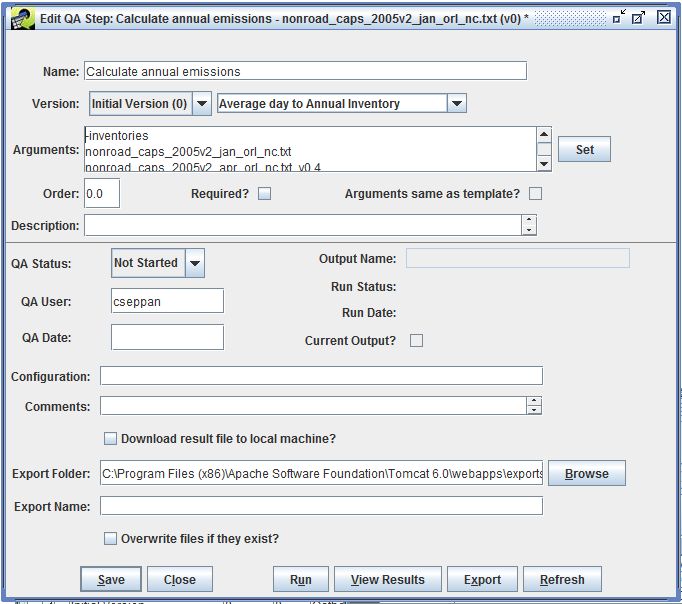
Click the Save button at the bottom of the Edit QA Step window to save the QA step. This QA step can now be run as described in Section 4.4.
The Compare Datasets QA program allows you to aggregate and compare datasets using a variety of grouping options. You can compare datasets with the same dataset type or different types. In this section, we’ll set up a QA step to compare the average day emissions from two ORL nonroad inventories by SCC and pollutant.
First, we’ll select a dataset to associate the QA step with. In this example, we’ll be comparing January and February emissions using the January dataset as the base inventory. The EMF doesn’t dictate which dataset should have the QA step associated with it so we’ll choose the base dataset as a convention. From the Dataset Manager, select the January inventory (shown in Figure 4-24) and click the Edit Properties button.
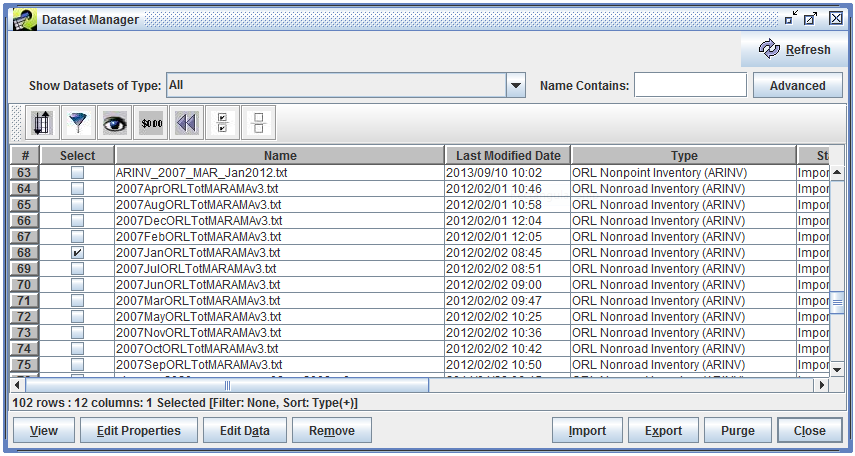
Open the QA tab (shown in Figure 4-25) and click Add Custom to add a new QA step.
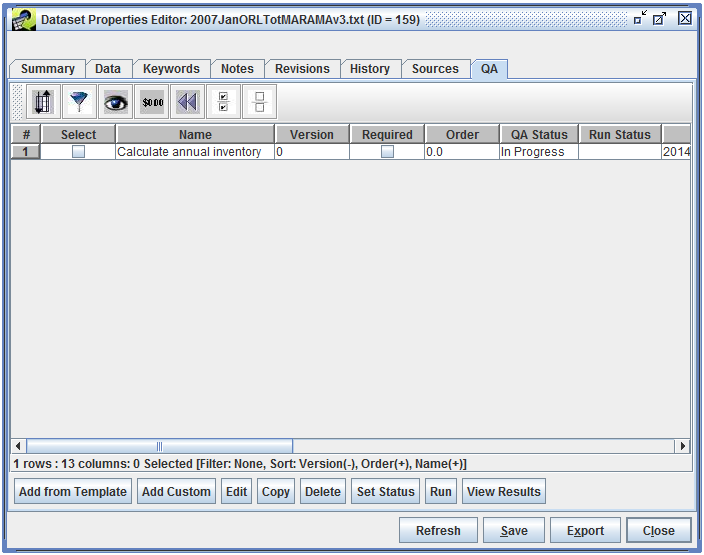
In the Add Custom QA Step dialog shown in Figure 4-26, enter a name for the new QA step like “Compare to February”. Use the Program pull-down menu to select the QA program “Compare Datasets”.
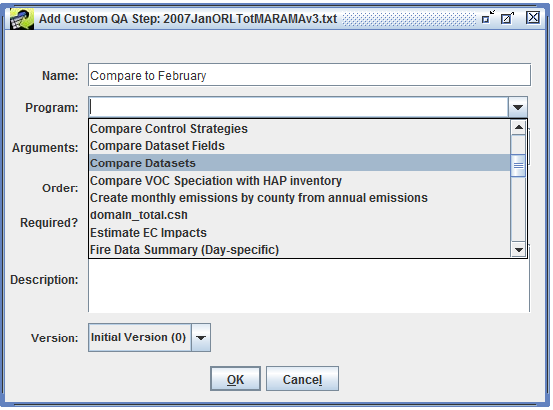
You can enter a description of the QA step as shown in Figure 4-27. Then click OK to save the QA step. We’ll be setting up the arguments to the Compare Datasets QA program in just a minute.
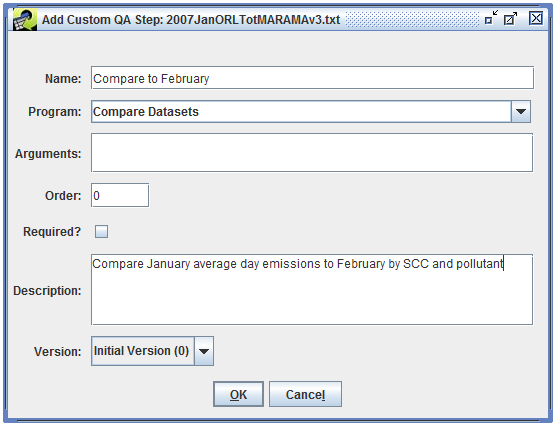
Back in the QA tab of the Dataset Properties Editor, select the newly created QA step and click the Edit button (see Figure 4-28).
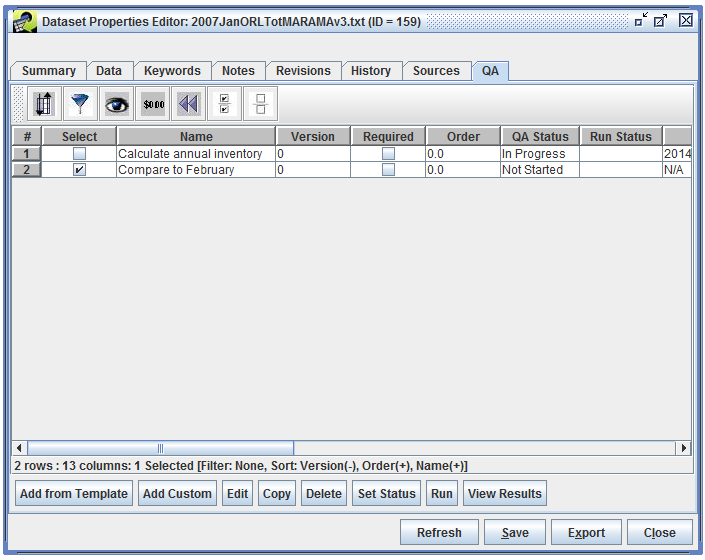
In the Edit QA Step window (shown in Figure 4-29), click the Set button to the right of the Arguments textbox.
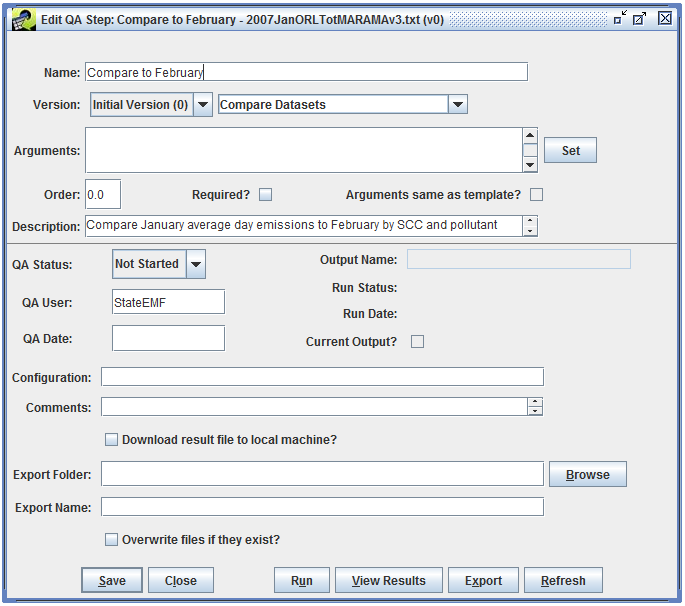
A custom dialog is displayed (Figure 4-30) to help you set up the arguments needed by the Compare Datasets QA program.
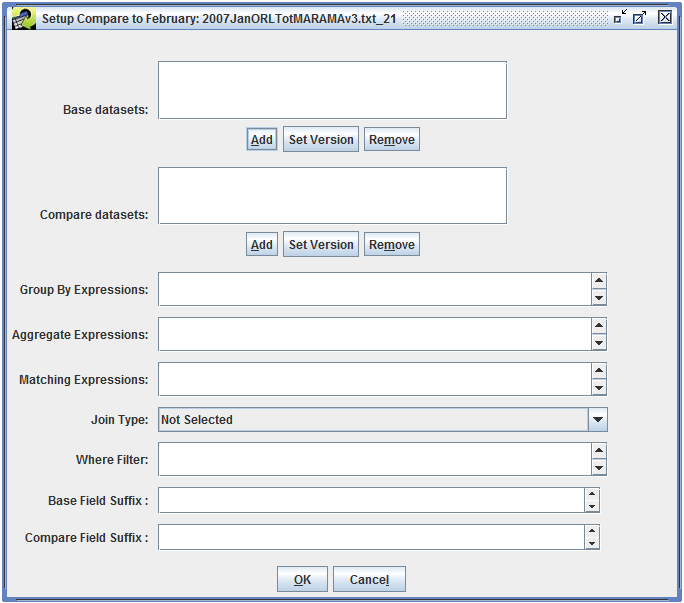
To get started, we’ll set the base datasets. Click the Add button underneath the Base Datasets area to bring up the Select Datasets dialog shown in Figure 4-31.
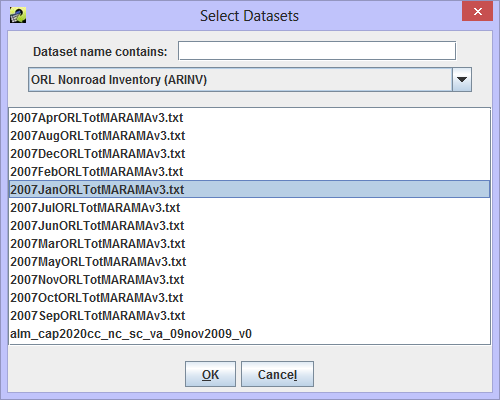
Select one or more datasets to use as the base datasets in the comparison. For this example, we’ll select the January inventory by clicking on the dataset name. Then click OK to close the dialog and return to the setup dialog. The setup dialog now shows the selected base dataset as in Figure 4-32.
Next, we’ll add the dataset we want to compare against by clicking the Add button underneath the Compare Datasets area. The Select Datasets dialog is displayed like in Figure 4-33. We’ll select the February inventory and click the OK button.
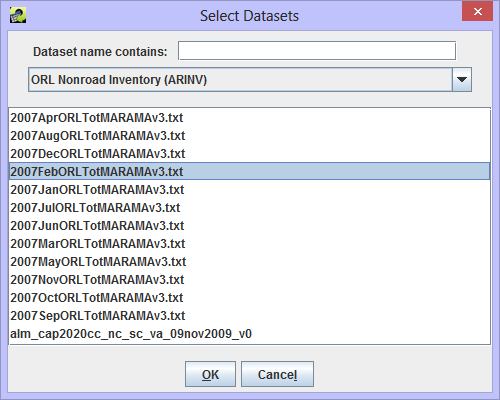
Returning to the setup dialog, the comparison dataset is now set as shown in Figure 4-34.
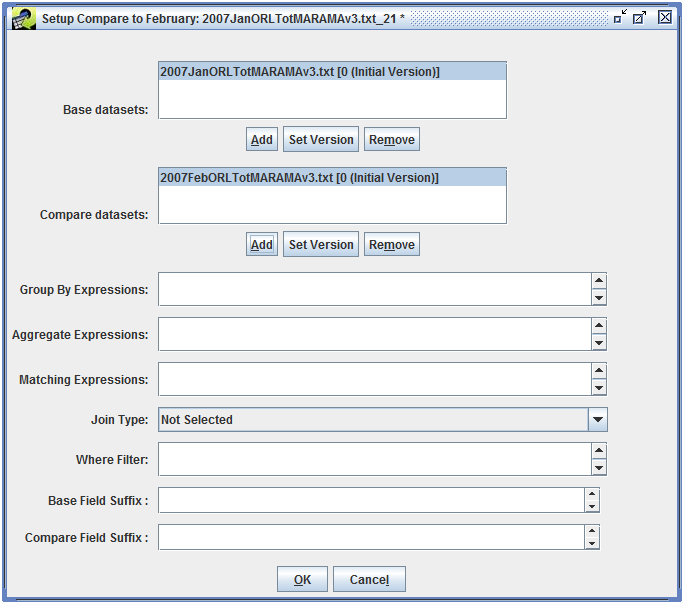
The list of base and comparison datasets includes which version of the data will be used in the QA step. For example, the base dataset 2007JanORLTotMARAMAv3.txt [0 (Initial Version)] indicates that version 0 (named “Initial Version”) will be used. When you select the base and comparison datasets, the EMF automatically uses each dataset’s Default Version. If any of the datasets have a different version that you would like to use for the QA step, select the dataset name and then click the Set Version button underneath the selected dataset. The Set Version dialog shown in Figure 4-35 lets you pick which version of the dataset you would like to use.
Next, we need to tell the Compare Datasets QA program how to compare the two datasets. We’re going to sum the average-day emissions in each dataset by SCC and pollutant and then compare the results from January to February. In the ORL Nonroad Inventory dataset type, the SCCs are stored in a field called scc, the pollutant codes are stored in a column named poll, and the average-day emissions are stored in a field called avd_emis. In the Group By Expressions textbox, type scc, press Enter, and then type poll. In the Aggregate Expressions textbox, type avd_emis. Figure 4-36 shows the setup dialog with the arguments entered.
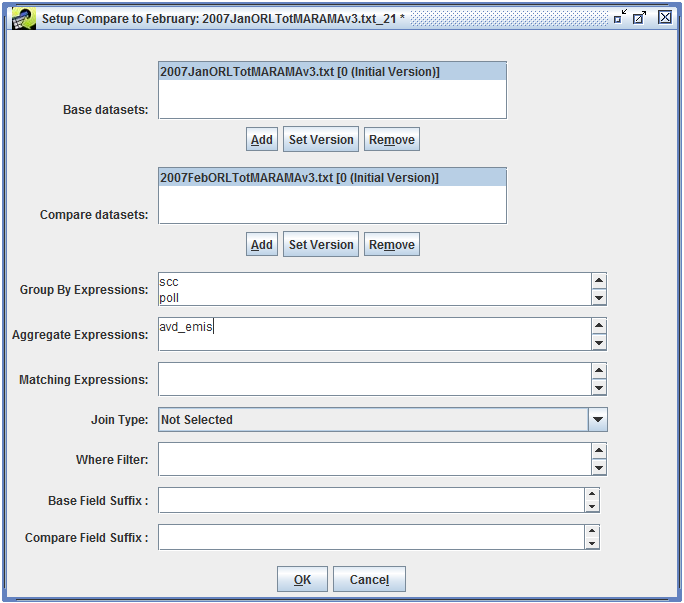
In this example, we’re comparing two datasets of the same type (ORL Nonroad Inventory). This means that the data field names will be consistent between the base and comparison datasets. When you compare datasets with different types, the field names might not match. The Matching Expressions textbox allows you to define how the fields from the base dataset should be matched to the comparison dataset. For this case, we don’t need to enter anything in the Matching Expressions textbox or any of the remaining fields in the setup dialog. The Compare Datasets arguments are described in more detail in Section 4.8.1.
In the setup dialog, click OK to save the arguments and return to the Edit QA Step window. The Arguments textbox now lists the arguments that we set up in the previous step (see Figure 4-37).
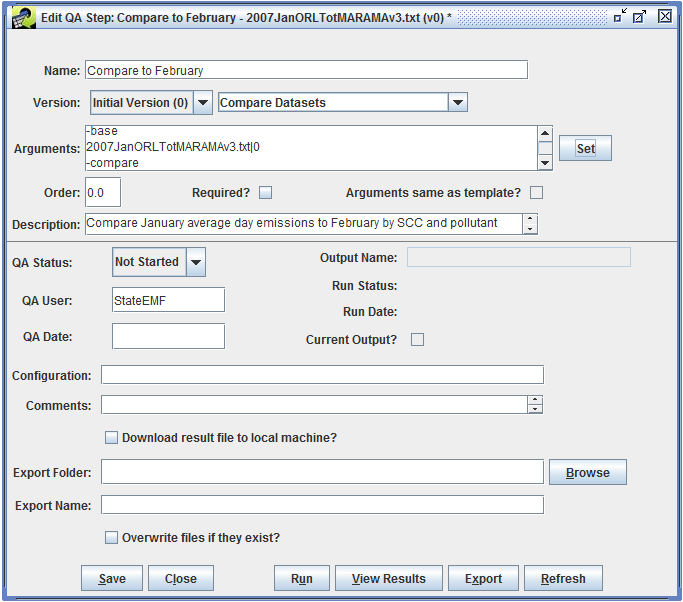
The QA step is now ready to run. Click the Run button to start running the QA step. A message is displayed at the top of the window as shown in Figure 4-38.
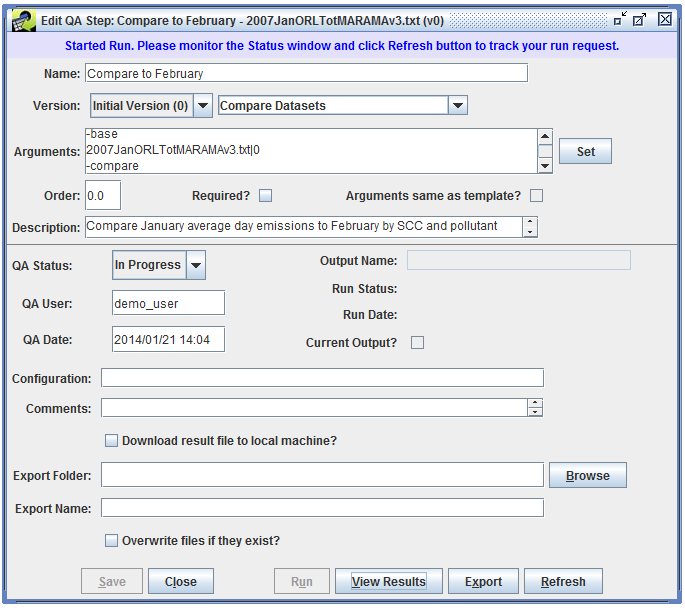
In the Status window, you’ll see a message about starting to run the QA step followed by a completion message once the QA step has finished running. Figure 4-39 shows the two status messages.

Once the status message
Completed running QA step ‘Compare to February’ for Version ‘Initial Version’ of Dataset ‘2007JanORLTotMARAMAv3.txt’
is displayed, the QA step has finished running. In the Edit QA Step window, click the Refresh button to display the latest information about the QA step. The fields Run Status and Run Date will be populated with the latest run information as shown in Figure 4-40.
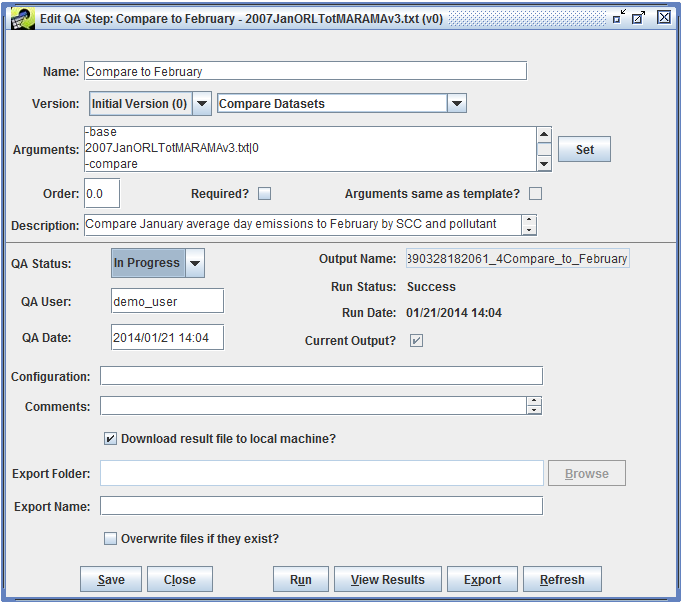
Now, we can view the QA step results or export the results. First, we’ll view the results inside the EMF client. Click the View Results button to open the View QA Step Results window as shown in Figure 4-41.
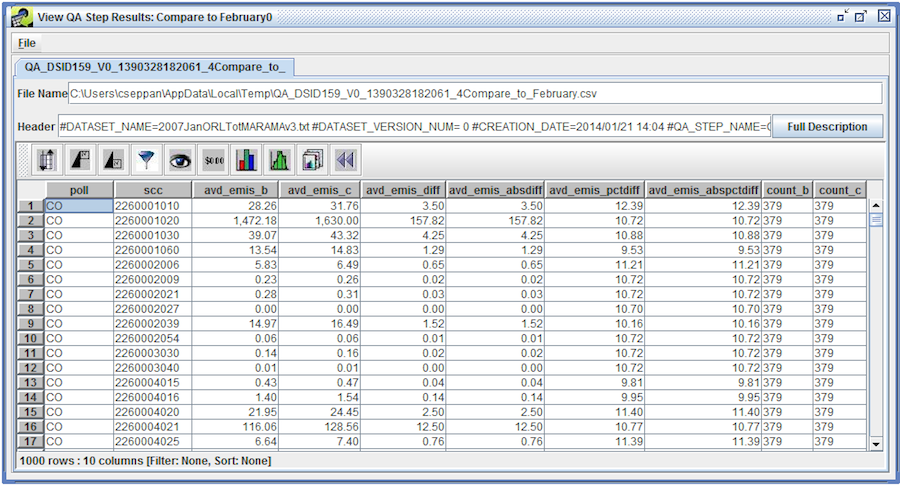
Table 4-1 describes each column in the QA step results.
| Column Name | Description |
|---|---|
poll |
Pollutant code |
scc |
SCC code |
avd_emis_b |
Summed average-day emissions from base dataset (January) for this pollutant and SCC |
avd_emis_c |
Summed average-day emissions from comparison dataset (February) for this pollutant and SCC |
avd_emis_diff |
avd_emis_c - avd_emis_b |
avd_emis_absdiff |
Absolute value of avd_emis_diff |
avd_emis_pctdiff |
100 * (avd_emis_diff / avd_emis_b) |
avd_emis_abspctdiff |
Absolute value of avd_emis_pctdiff |
count_b |
Number of records from base dataset included in this row’s results |
count_c |
Number of records from comparison dataset included in this row’s results |
To export the QA step results, return to the Edit QA Step window as shown in Figure 4-42. Select the checkbox labeled Download result file to local machine?. In this example, we have entered an optional Export Name for the output file. If you don’t enter an Export Name, the output file will use an auto-generated name. Click the Export button.
The Export QA Step Results dialog will be displayed as shown in Figure 4-43. For more information about the Row Filter option, see Section 4.5. To export all the result records, click the Finish button.
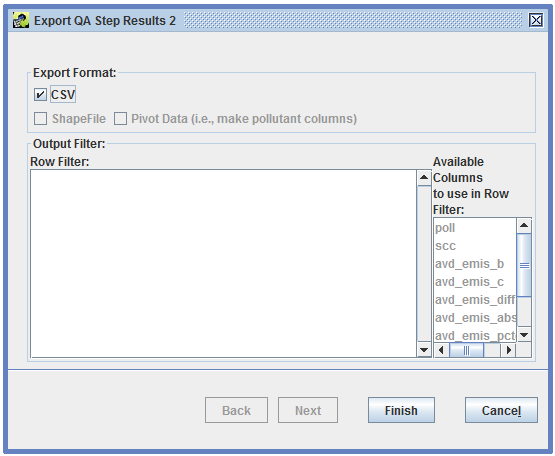
Back in the Edit QA Step window, a message is displayed at the top of the window indicating that the export has started. See Figure 4-44.
Check the Status window to see the status of the export as shown in Figure 4-45.
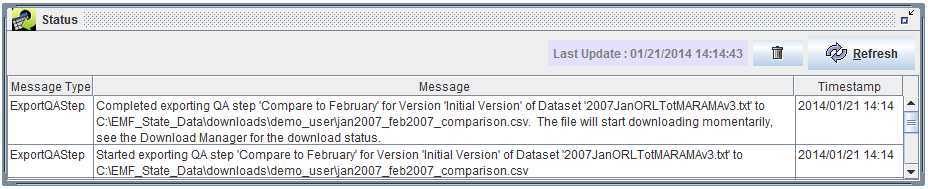
Once the export is complete, the file will start downloading to your computer. Open the Downloads window to check the download status. Once the progress bar reaches 100%, the download is complete. Right click on the results file and select Open Containing Folder as shown in Figure 4-46.
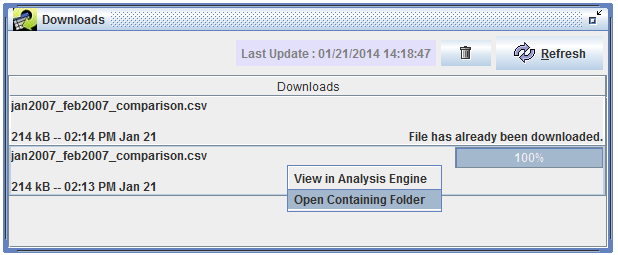
Figure 4-47 shows the downloaded file in Windows Explorer. By default, files are downloaded to a temporary directory on your computer. Some disk cleanup programs can automatically delete files in temporary directories; you should move any downloads you want to keep to a more permanent location on your computer.
The downloaded file is a CSV (comma-separated values) file which can be opened in Microsoft Excel or other spreadsheet programs. Double-click the filename to open the file. Figure 4-48 shows the QA step results in Microsoft Excel.
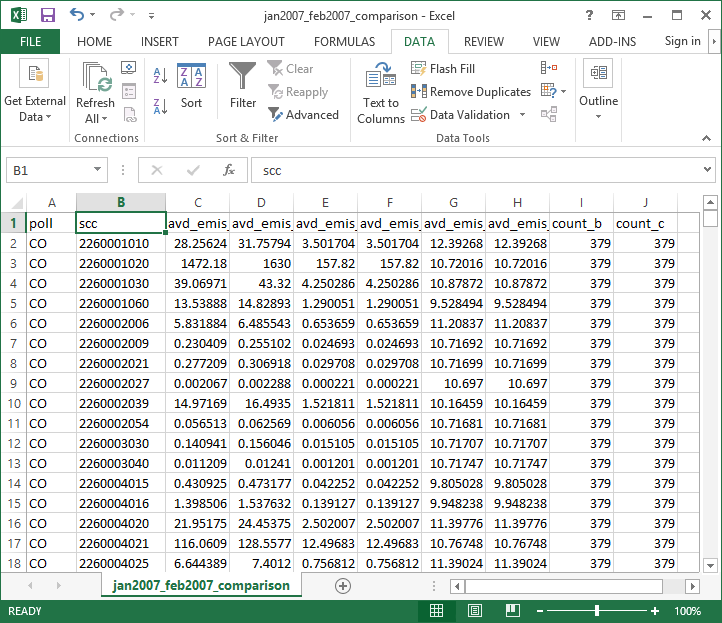
The Group By Expressions are a list of columns/expressions that are used to group the dataset records for aggregation. The expressions must contain valid columns from either the base or comparison datasets. If a column exists only in the base or compare dataset, then a Matching Expression must be specified in order for a proper mapping to happen during the comparison analysis. A group by expression can be aliased by adding the AS <alias> clause to the expression; this alias is used as the column name in the QA step results. A group by expression can also contain SQL functions such as substring or string concatenation using ||.
Sample Group By Expressions
scc AS scc_code
substring(fips, 1, 2) as fipsst
or
fipsst||fipscounty as fips
substring(scc, 1, 5) as scc_lv5
The Aggregate Expressions are a list of columns/expressions that will be aggregated (summed) using the specified group by expressions. The expressions must contain valid columns from either the base or comparison datasets. If a column exists only in the base or compare dataset, then a Matching Expression must be specified in order for a proper mapping to happen during the comparison analysis.
Sample Aggregate Expressions
ann_emis
avd_emis
The Matching Expressions are a list of expressions used to match base dataset columns/expressions to comparison dataset columns/expressions. A matching expression consists of three parts: the base dataset expression, the equals sign, and the comparison dataset expression (i.e. base_expression=comparison_expression).
Sample Matching Expressions
substring(fips, 1, 2)=substring(region_cd, 1, 2)
scc=scc_code
ann_emis=emis_ann
avd_emis=emis_avd
fips=fipsst||fipscounty
The Join Type specifies which type of SQL join should be used when performing the comparison.
| Join Type | Description |
|---|---|
| INNER JOIN | Only include rows that exist in both the base and compare datasets based on the group by expressions |
| LEFT OUTER JOIN | Include all rows from the base dataset, only include rows from the compare dataset that meet the group by expressions |
| RIGHT OUTER JOIN | Include all rows from the compare dataset, only include rows from the base dataset that meet the group by expressions |
| FULL OUTER JOIN | Include all rows from both the base and compare datasets |
The default join type is FULL OUTER JOIN.
The Where Filter is a SQL WHERE clause that is used to filter both the base and comparison datasets. The expressions in the WHERE clause must contain valid columns from either the base or comparison datasets. If a column exists only in the base or compare dataset, then a Matching Expression must be specified in order for a proper mapping to happen during the comparison analysis.
Sample Row Filter
substring(fips, 1, 2) = '37' and SCC_code in ('10100202', '10100203')
or
fips like '37%' and SCC_code like '101002%'
The Base Field Suffix is appended to the base aggregate expression name that is returned in the output. For example, an Aggregate Expression ann_emis with a Base Field Suffix 2005 will be returned as ann_emis_2005 in the QA step results.
The Compare Field Suffix is appended to the comparison aggregate expression name that is returned in the output. For example, an Aggregate Expression ann_emis with a Compare Field Suffix 2008 will be returned as ann_emis_2008 in the QA step results.
Figure 4-49 shows the setup dialog for the following example of the Compare Datasets QA program. We are setting up a plant level comparison of a set of two inventories (EGU and non-EGU) versus another set of two inventories (EGU and non-EGU). All four inventories are the same dataset type. The annual emissions will be grouped by FIPS code, plant ID, and pollutant. There is no mapping required because the dataset types are identical; the columns fips, plantid, poll, and ann_emis exist in both sets of datasets. This comparison is limited to the state of North Carolina via the Where Filter:
substring(fips, 1, 2)='37'
The QA step results will have columns named ann_emis_base, ann_emis_compare, count_base, and count_compare using the Base Field Suffix and Compare Field Suffix.
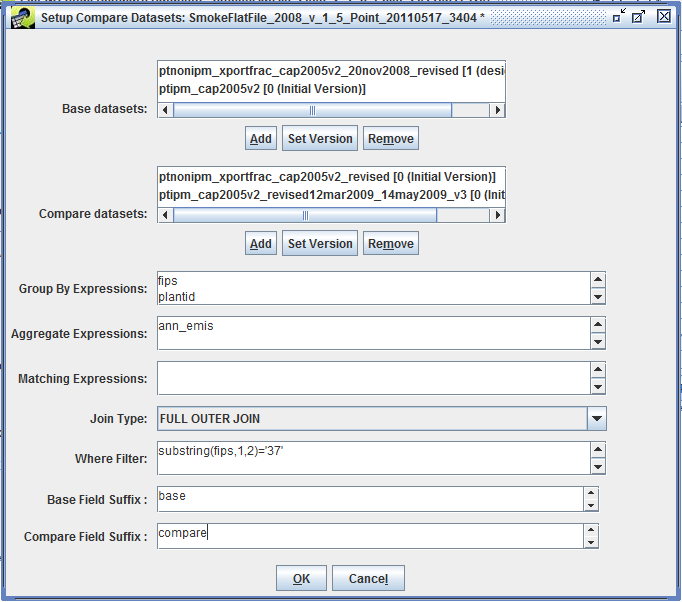
Figure 4-50 shows the setup dialog for a second example of the Compare Datasets QA program. This example takes a set of ORL nonpoint datasets and compares it to a single FF10 nonpoint inventory. We are grouping by state (first two digits of the FIPS code) and pollutant. A mapping expression is needed between the ORL column fips and the FF10 column region_cd:
substring(fips, 1, 2)=substring(region_cd, 1, 2)
Another mapping expression is needed between the columns ann_emis and ann_value:
ann_emis=ann_value
No mapping is needed for pollutant because both dataset types use the same column name poll. This comparison is limited to three states and to sources that have annual emissions greater than 1000 tons. These constraints are specified via the Where Filter:
substring(fips, 1, 2) in ('37','45','51') and ann_emis > 1000
In the QA step results, the base dataset column will be named ann_emis_2002 and the compare dataset column will be named ann_emis_2008.
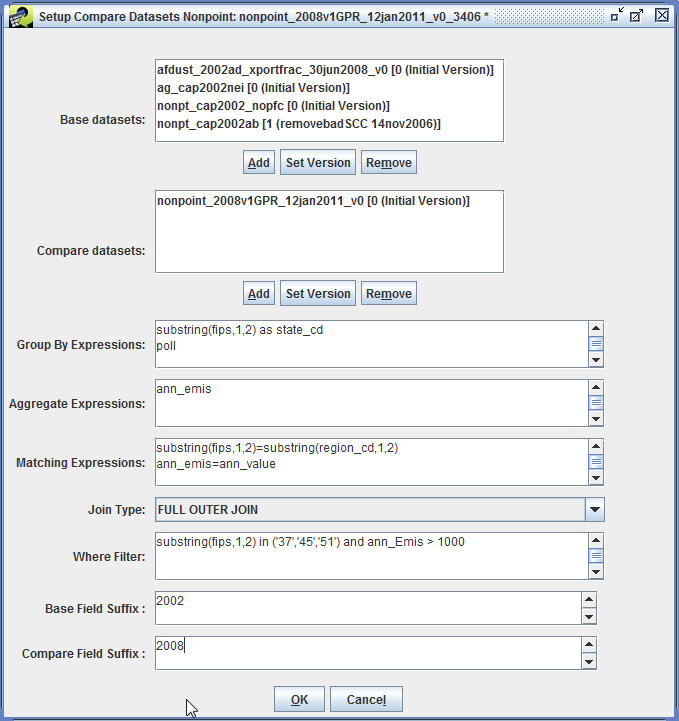
Suppose you have an ORL nonroad inventory that contains average-day emissions instead of annual emissions. The QA step templates that can generate inventory summaries report summed annual emissions. If you want to get a report of the average-day emissions, you can create a custom SQL QA step.
First, let’s look at the structure of a SQL QA step created from a QA step template. Figure 4-51 shows a QA step that generates a summary of the annual emissions by county and pollutant.
This QA step uses a custom SQL query shown in the Arguments textbox:
select FIPS, POLL, sum(ann_emis) as ann_emis from $TABLE[1] e group by FIPS, POLL order by FIPS, POLL
For the ORL nonroad inventory dataset type, the annual emission values are stored in a database column named ann_emis while the average-day emissions are in a column named avd_emis. For any dataset you can see the names of the underlying data columns by viewing the raw data as described in Section 3.6.
To create an average-day emissions report, we’ll need to switch ann_emis in the above SQL query to avd_emis. In addition, the annual emissions report sums the emissions across the counties and pollutants. For average-day emissions, it might make more sense to compute the average emissions by county and pollutant. In the SQL query we can change sum(ann_emis) to avg(avd_emis) to call the SQL function which computes averages.
Our final revised SQL query is
select FIPS, POLL, avg(avd_emis) as avd_emis from $TABLE[1] e group by FIPS, POLL order by FIPS, POLL
Once we know what SQL query to run, we’ll create a custom QA step. Section 4.3 describes how to add a custom QA step to a dataset. Figure 4-52 shows the new custom QA step with a name assigned and the Program pull-down menu set to SQL so that the custom QA step will run a SQL query. Our custom SQL query is pasted into the Arguments textbox.
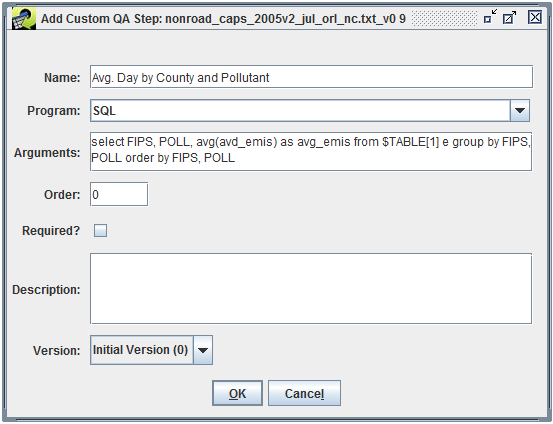
Click the OK button to save the QA step. The newly added QA step is now shown in the list of QA steps for the dataset (Figure 4-53).
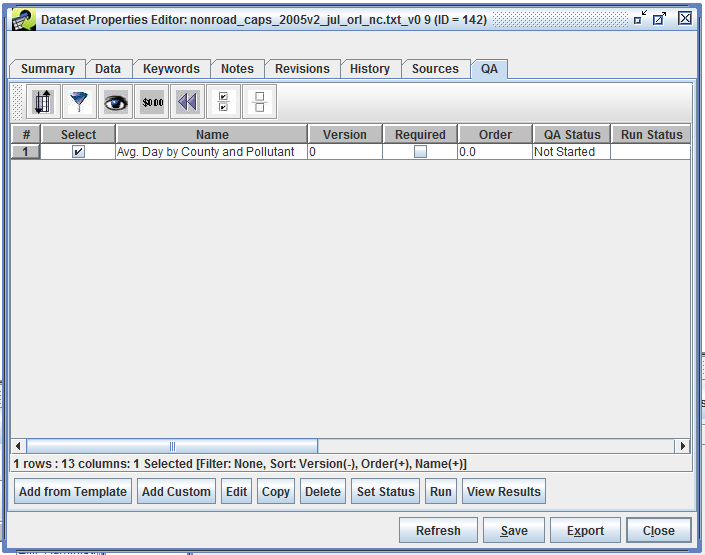
At this point, you can run the QA step as described in Section 4.4 and view and export the QA step results (Section 4.5) just like any other QA step.
What if our custom SQL had a typo? Suppose we accidently entered the average-day emissions column name as avg_emis instead of avd_emis. When the QA step is run, it will fail to complete successfully. The Status window will display a message like
Failed to run QA step Avg. Day by County and Pollutant for Version ‘Initial Version’ of Dataset <dataset name>. Check the query -ERROR: column “avg_emis” does not exist
Other types of SQL errors will be displayed in the Status window as well. If the SQL query uses an invalid function name like average(avd_emis) instead of avg(avd_emis), the Status window message is
Failed to run QA step Avg. Day by County and Pollutant for Version ‘Initial Version’ of Dataset <dataset name>. Check the query -ERROR: function average(double precision) does not exist
Each of the QA steps that create summaries use a customized SQL syntax that is very similar to standard SQL, except that it includes some EMF-specific concepts that allow the queries to be defined generally and then applied to specific datasets as needed. For example, the EMF syntax for the “Summarize by SCC and Pollutant” query is:
select SCC, POLL, sum(ann_emis) as ann_emis from $TABLE[1] e group by SCC, POLL order by SCC, POLL
The only difference between this and standard SQL is the use of the $TABLE[1] syntax. When this query is run, the $TABLE[1] portion of the query is replaced with the table name that contains the dataset’s data in the EMF database. Most datasets have their own tables in the EMF schema, so you do not normally need to worry about selecting only the records for the specific dataset of interest. The customized syntax also has extensions to refer to another dataset and to refer to specific versions of other datasets using tokens other than $TABLE. For the purposes of this discussion, it is sufficient to note that these other extensions exist.
Some of the summaries are constructed using more complex queries that join information from other tables, such as the SCC and pollutant descriptions, and to account for any missing descriptions. For example, the syntax for the “Summarize by SCC and Pollutant with Descriptions” query is:
select e.SCC,
coalesce(s.scc_description,'AN UNSPECIFIED DESCRIPTION')::character varying(248) as scc_description,
e.POLL,
coalesce(p.descrptn,'AN UNSPECIFIED DESCRIPTION')::character varying(11) as pollutant_code_desc,
coalesce(p.name,'AN UNSPECIFIED SMOKE NAME')::character varying(11) as smoke_name,
p.factor,
p.voctog,
p.species,
coalesce(sum(ann_emis), 0) as ann_emis,
coalesce(sum(avd_emis), 0) as avd_emis
from $TABLE[1] e
left outer join reference.invtable p on e.POLL=p.cas
left outer join reference.scc s on e.SCC=s.scc
group by e.SCC,e.POLL,p.descrptn,s.scc_description,p.name,p.factor,p.voctog,p.species
order by e.SCC, p.name
This query is quite a bit more complex, but is still supported by the EMF QA step processing system.
Problem:
On startup, an error message is displayed like Figure 5-1:
"The EMF client was not able to contact the server due to this error:
(504)Server doesn’t respond at all."
or
(504)Server denies connection.
Solution:
The EMF client application was not able to connect to the EMF server. This could be due to a problem on your computer, the EMF server, or somewhere in between.
If you are connecting to a remote EMF server, first check your computer’s network connection by loading a page like google.com in your web browser. You must have a working network connection to use the EMF client.
Next, check the server location in the EMF client start up script C:\EMF_State\EMFClient.bat. Look for the line
set TOMCAT_SERVER=http://<server location>:8080
You can directly connect to the EMF server by loading
http://<server location>:8080/emf/services
in your web browser. You should see a response similar to Figure 5-2.
If you can’t connect to the EMF server or don’t get a response, then the EMF server may not be running. Contact the EMF server administrator for further help.
Problem:
When I click the Datasets item from the main Manage menu, nothing happens and I can’t click on anything else.
Solution:
Clicking Datasets from the main Manage menu displays the Dataset Manager. In order to display this window, the EMF client needs to request a complete list of dataset types from the EMF server. If you are connecting to an EMF server over the Internet, fetching lists of data can take a while and the EMF client needs to wait for the data to be received. Try waiting to see if the Dataset Manager window appears.
Problem:
In the Dataset Manager, I selected Show Datasets of Type “All” and nothing happens and I can’t click on anything else.
Solution:
When displaying datasets of the selected type, the EMF client needs to fetch the details of the datasets from the EMF server. If you are connecting to an EMF server over the Internet or if there are many datasets imported into the EMF, loading this data can take a long time. Try waiting to see if the list of datasets is displayed. Rather than displaying all datasets, you may want to pick a single dataset type or use the Advanced search to limit the list of datasets that need to be loaded from the EMF server.
The EMF server consists of a database, file storage, and the server application which handles requests from the clients and communicates with the database.
The database server is PostgreSQL version 9.2 or later. For ShapeFile export, you will need the PostGIS module installed.
The server application is a Java executable that runs in the Apache Tomcat servlet container. You will need Apache Tomcat 6.0 or later.
The server components can run on Windows, Linux, or Mac OS X.
The EMF client application communicates with the server on port 8080. For the client application, the EMFClient.bat launch script specifies the server location and port via the setting
set TOMCAT_SERVER=http://<server address>:8080
In order to import data into the EMF, the files must be locally accessible by the server. Depending on your setup, you may want to mount a network drive on the server or allow SFTP connections for users to upload files.
Inside the EMF client, users with administrative privileges have access to additional management options.
EMF administrators can reset users passwords. Administrators can also create new users.
Administrators can create and edit dataset types. Administrators can also add QA step templates to dataset types.